Hello readers,
This is the first part from the 4-part CUDA-Aware-MPI series.
In this blog series, we will use only NVIDIA GPGPUs and assume that the user know basics about CUDA-Aware-MPI from the official blogpost : https://developer.nvidia.com/blog/introduction-cuda-aware-mpi/[1]
MPI is widely used library for distributed programming. It allows your parallel code to scale across different nodes in a supercomputing cluster. So comes the need to support direct GPU-to-GPU communication across different nodes. CUDA-Aware-MPI allows the user to directly specify the GPU buffer address in the MPI API calls. It is not required by the user to explicitly copy the contents from GPU buffer to CPU buffer and then use CPU buffer address in MPI calls to communicate the contents of GPU buffer. The process of copying the contents of a GPU buffer from GPU memory to CPU memory is called staging. We will use the word ‘staging‘ many times in this series. Staging is handled by MPI internally and done whenever required. Staging can be done by MPI in various scenarios like communicating strided/non-contiguous data between GPUs or during internode GPU communication when GPUDirect RDMA driver is not present etc.
For the first post, I would like to point out the importance of understanding your node topology, with which comes the understanding of the bottlenecks/limitations. We then use the understanding from the node topology to verify the peak effective communication bandwidth (the communication bandwidth that can be achieved in real world and is less than theoretical communication bandwidth on paper).
We will use 3 different nodes:
- 8 x Nvidia A40 (40 GB DDR6) with 2 x 25 GbE between 2 nodes.
- 8 x Nvidia A100 (40 GB HBM2) with 2 x HDR200 between 2 nodes.
- 4 x Nvidia H100 (94GB HBM2e) with 4 x NDR200 between 2 nodes.
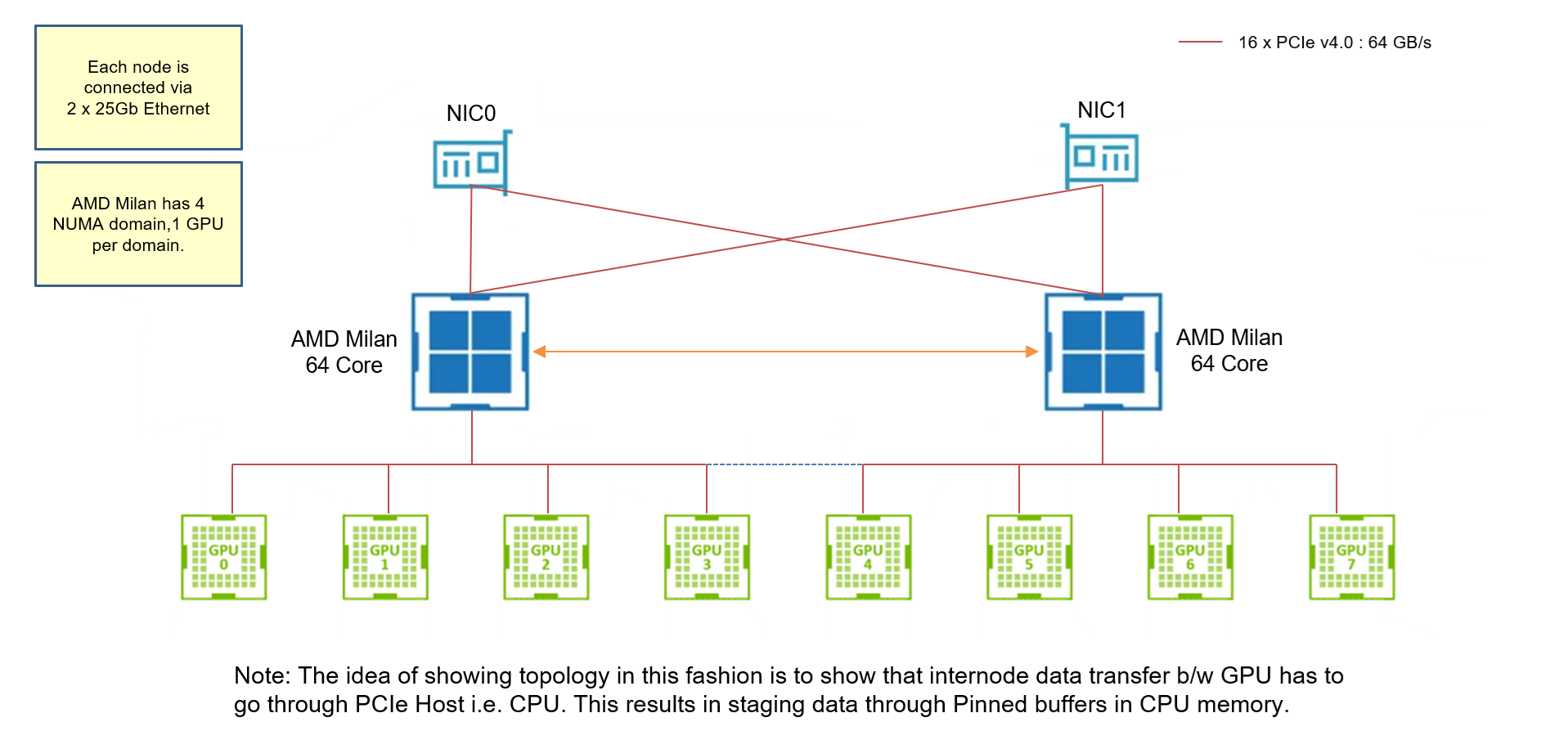
The node topology for A40 node is as follows:
The node topology for A100 node is as follows:
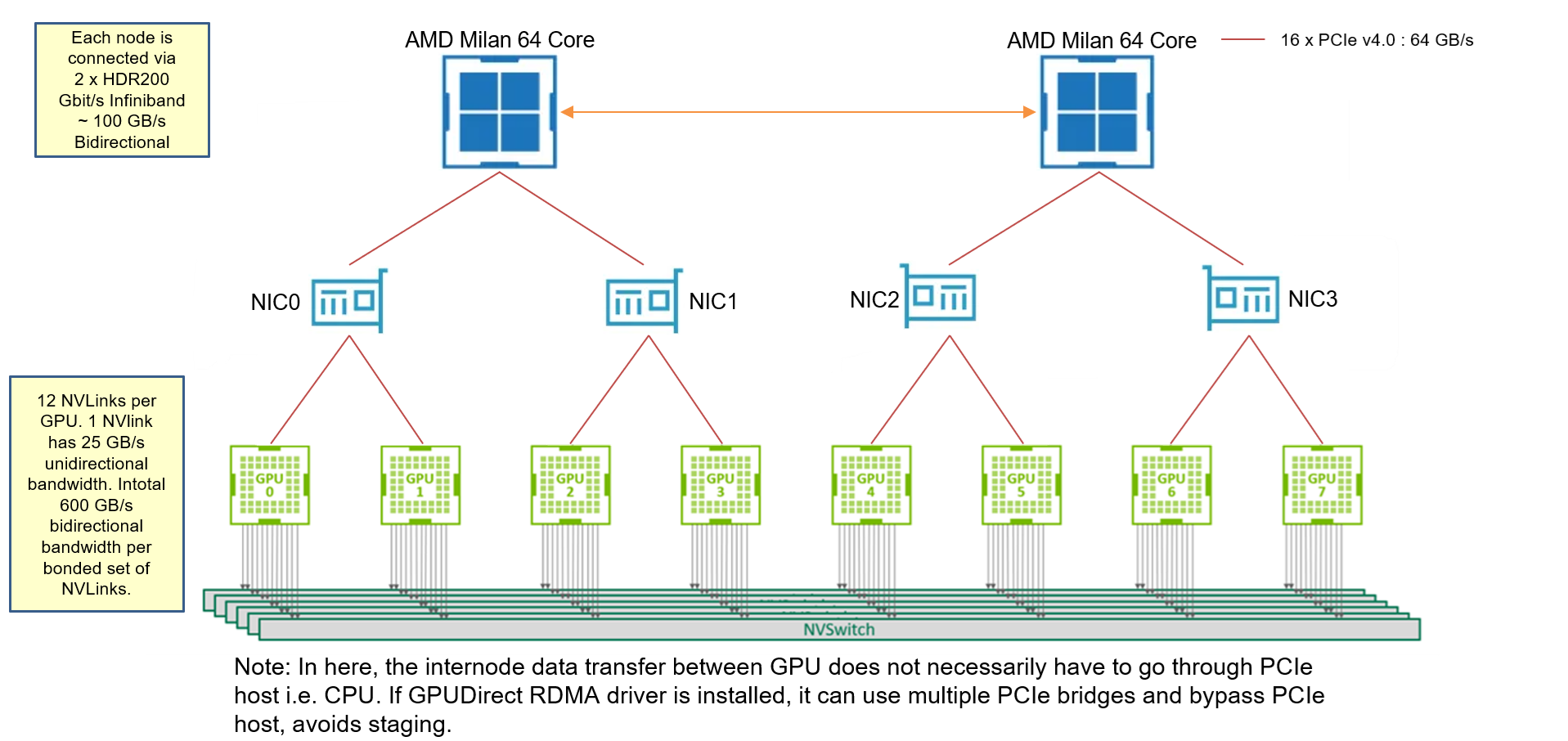
Note: A40 and A100 nodes (from the cluster I used) does not have GPUDirect RDMA drivers. Hence when performing Internode communication, MPI will stage data through CPU and then sends it to another node. But A40 and A100 nodes have GPUDirect P2P driver that allows GPU-to-GPU direct communication within one node. GPUDirect RDMA driver can be located using :
lsmod | grep "nvidia_peermem"
More about GPUDirect drivers can be found here: https://developer.nvidia.com/gpudirect
The node topology for H100 node is as follows:
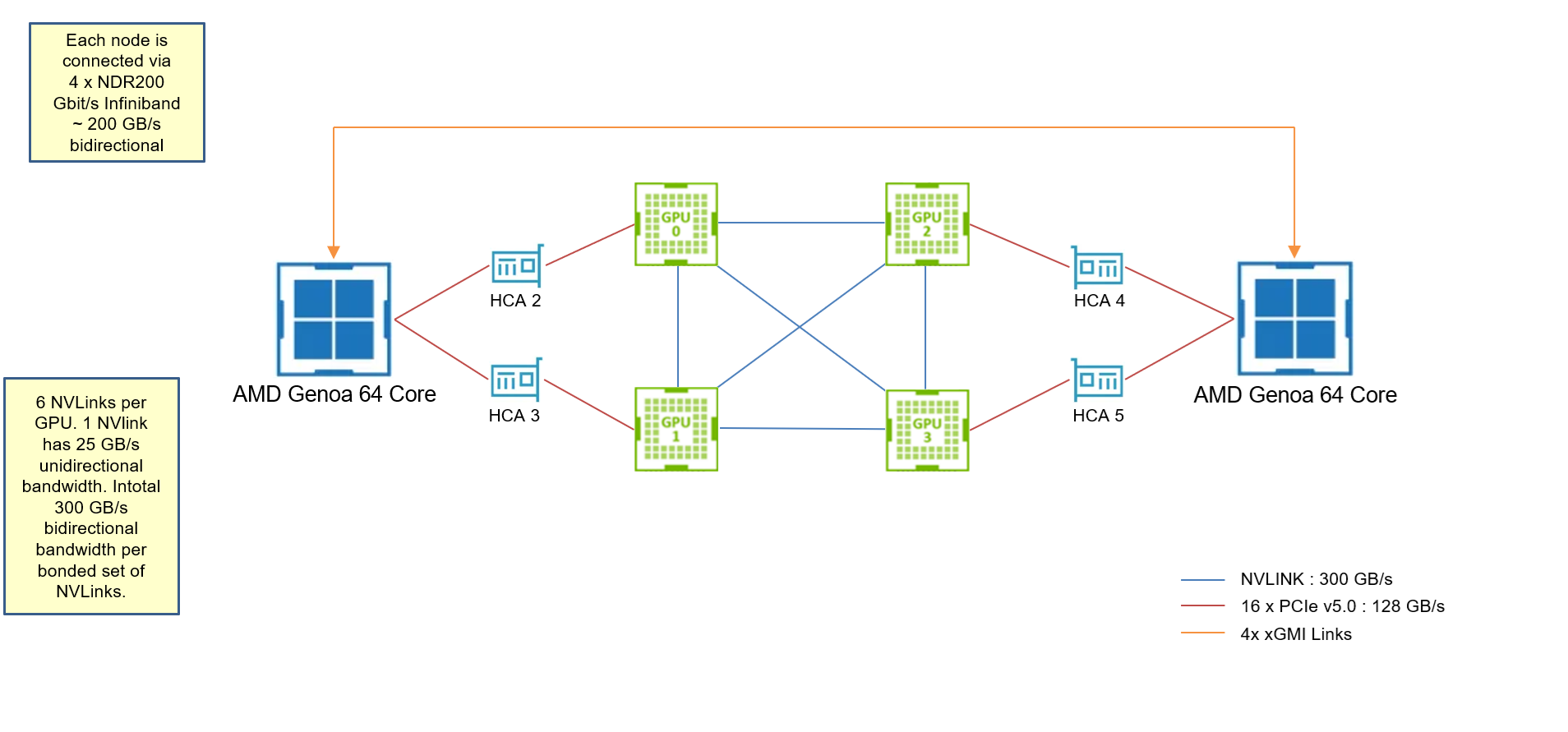
Note: H100 node (from the cluster I used) has GPUDirect RDMA driver installed. We shall observe the difference in effective communication bandwidth with/without the GPUDirect RDMA driver.
Note about NVLink bandwidth: The marketed NVLink bandwidth in white paper is always theoretical bidirectional bandwidth. That means 2 GPUs have to communicate with the other simultaneously to saturate the NVLink bandwidth. NVLink has multiple “sub-links” per direction and without simultaneous communication between 2 GPUs, the user may never saturate the full NVLink bandwidth.
Let us start by introducing the benchmark used to measure effective communication bandwidth. Since we want to saturate the communication interfaces (PCIe, NVLink, Infiniband), we have chose MPI Ping Ping benchmark. Ping Ping benchmark uses asynchronous bidirectional ISend/IRecv calls as shown below:
MPI_Request requests[2] = { MPI_REQUEST_NULL , MPI_REQUEST_NULL };
if(rank == 0){
MPI_Isend(d_A, N, MPI_DOUBLE, 1, tag1, MPI_COMM_WORLD, &requests[0]);
MPI_Irecv(d_A_1, N, MPI_DOUBLE, 1, tag2, MPI_COMM_WORLD, &requests[1]);
MPI_Waitall(2, requests, MPI_STATUSES_IGNORE);
}
else if(rank == 1){
MPI_Isend(d_A, N, MPI_DOUBLE, 0, tag2, MPI_COMM_WORLD, &requests[0]);
MPI_Irecv(d_A_1, N, MPI_DOUBLE, 0, tag1, MPI_COMM_WORLD, &requests[1]);
MPI_Waitall(2, requests, MPI_STATUSES_IGNORE);
}
This is a simple MPI Ping Ping benchmark that allows simultaneous bidirectional communication. We run this code for Intranode(within 1node) and Internode(between 2 nodes) setup. We will measure bandwidth for buffer lengths ranging from 8 Bytes to 1 GB.
The MPI Ping Ping Intranode benchmarks on A40 node are as follows:
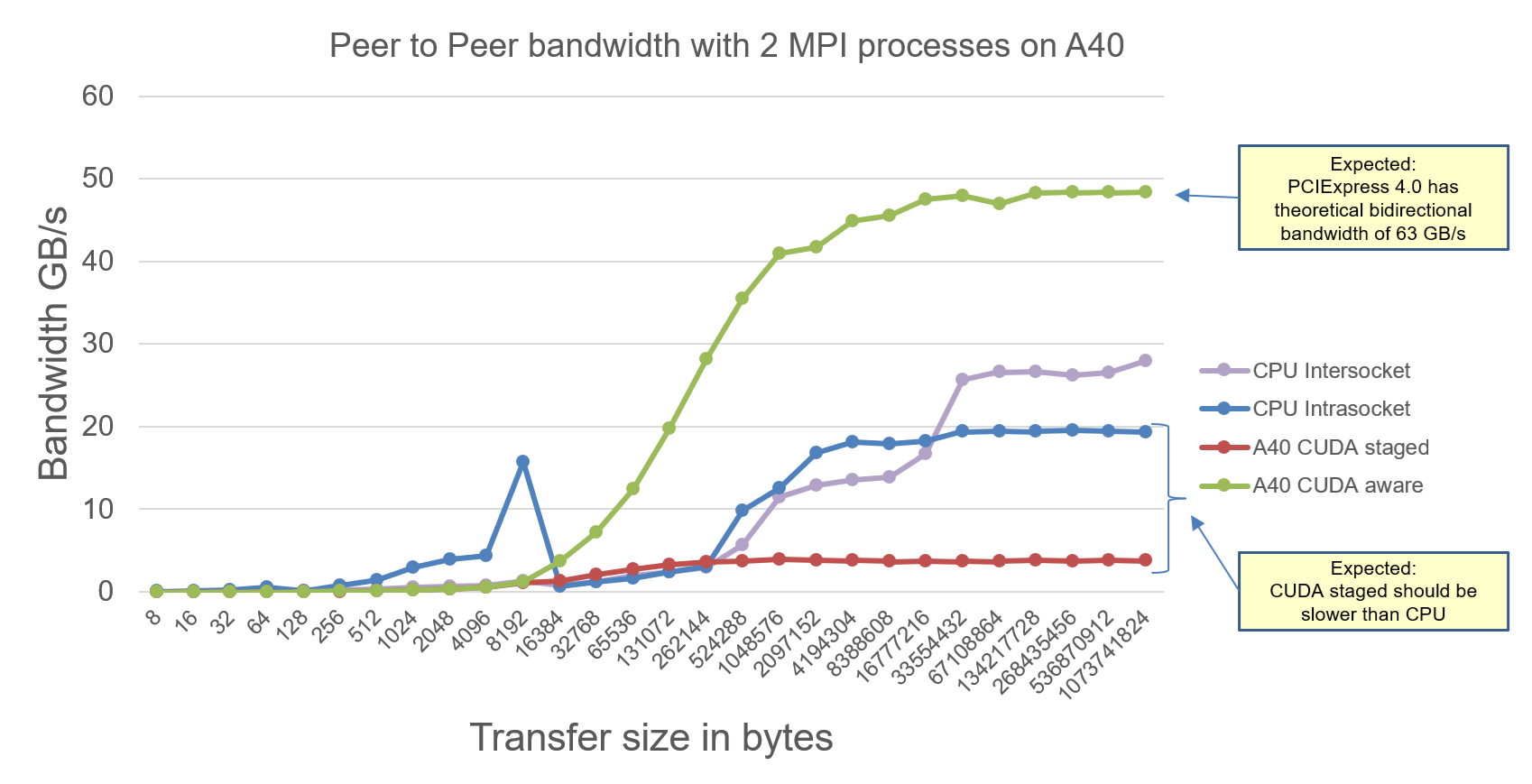
Explanation: We observe the expected effective bidirectional communication bandwidth measurements for 2 A40 GPUs communication within one node:
- CUDA-Aware-MPI program running on 2 A40 GPUs achieve maximum effective communication bandwidth of 48 GB/s which is less than theoretical communication bandwidth of 63 GB/s.
- CUDA-staged-MPI program, where we explicitly copy the GPU buffer to CPU and then communicate, is slower than pure CPU bidirectional communication, which is expected. The reason is simple. (GPU buffer copy to CPU + CPU communication time) > CPU communication time.
The MPI Ping Ping Internode benchmarks on A40 node are as follows:
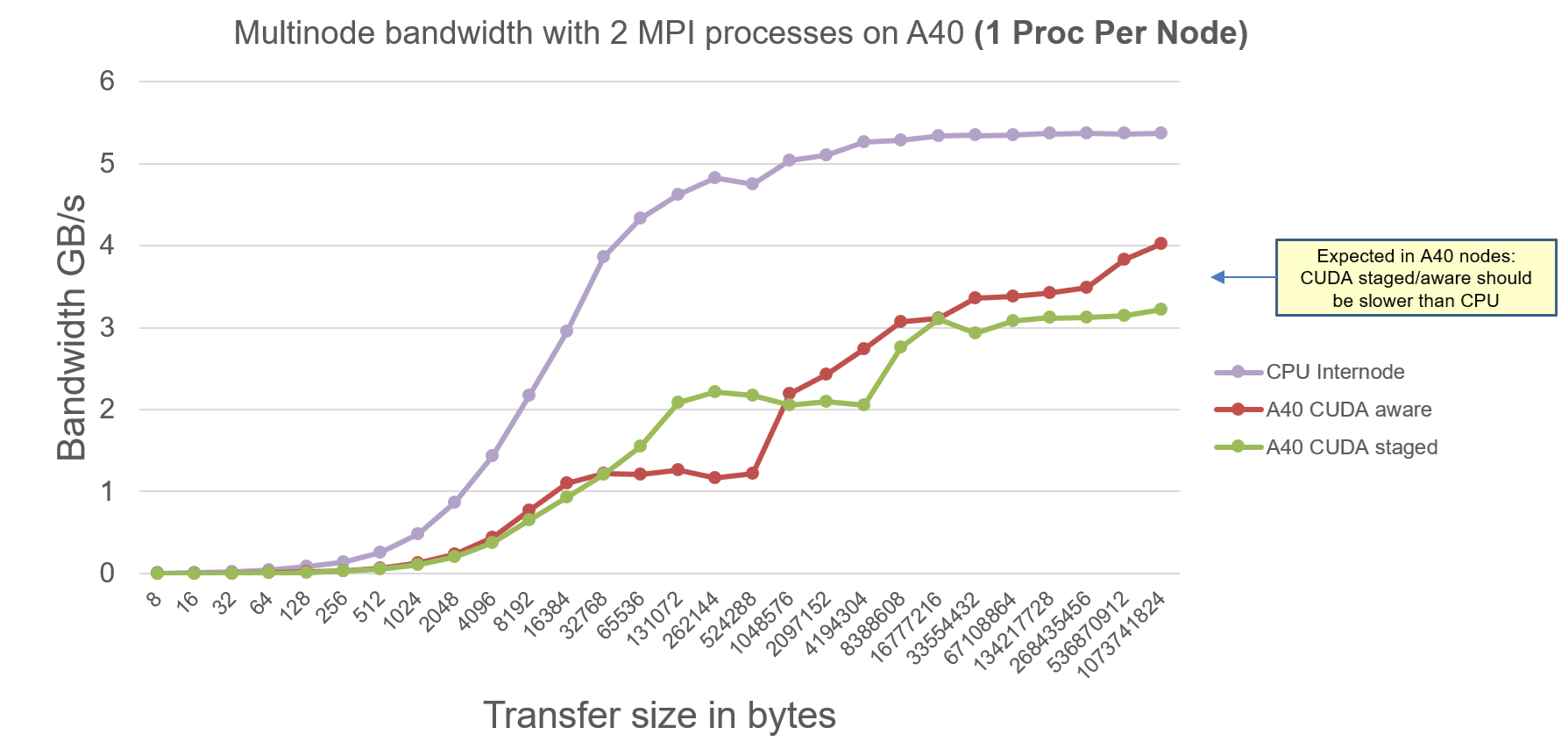
Explanation:
- We observe maximum effective bandwidth of 5.2 GB/s for CPU bidirectional communication, which is expected due to only 2 x 25GbE between 2 nodes.
- We observe CUDA-Aware-MPI is slower than CPU because there is no GPUDirect RDMA driver on A40 nodes. Hence the MPI internally stages data to CPU and then bidirectional communication takes place.
- CUDA-Aware-MPI has same effective communication bandwidth as CUDA-staged-MPI because there is little room for improvement from message pipelining. How CUDA-Aware-MPI leverages message pipelining is explained in [1].
The MPI Ping Ping Intranode benchmarks on A100 node are as follows:
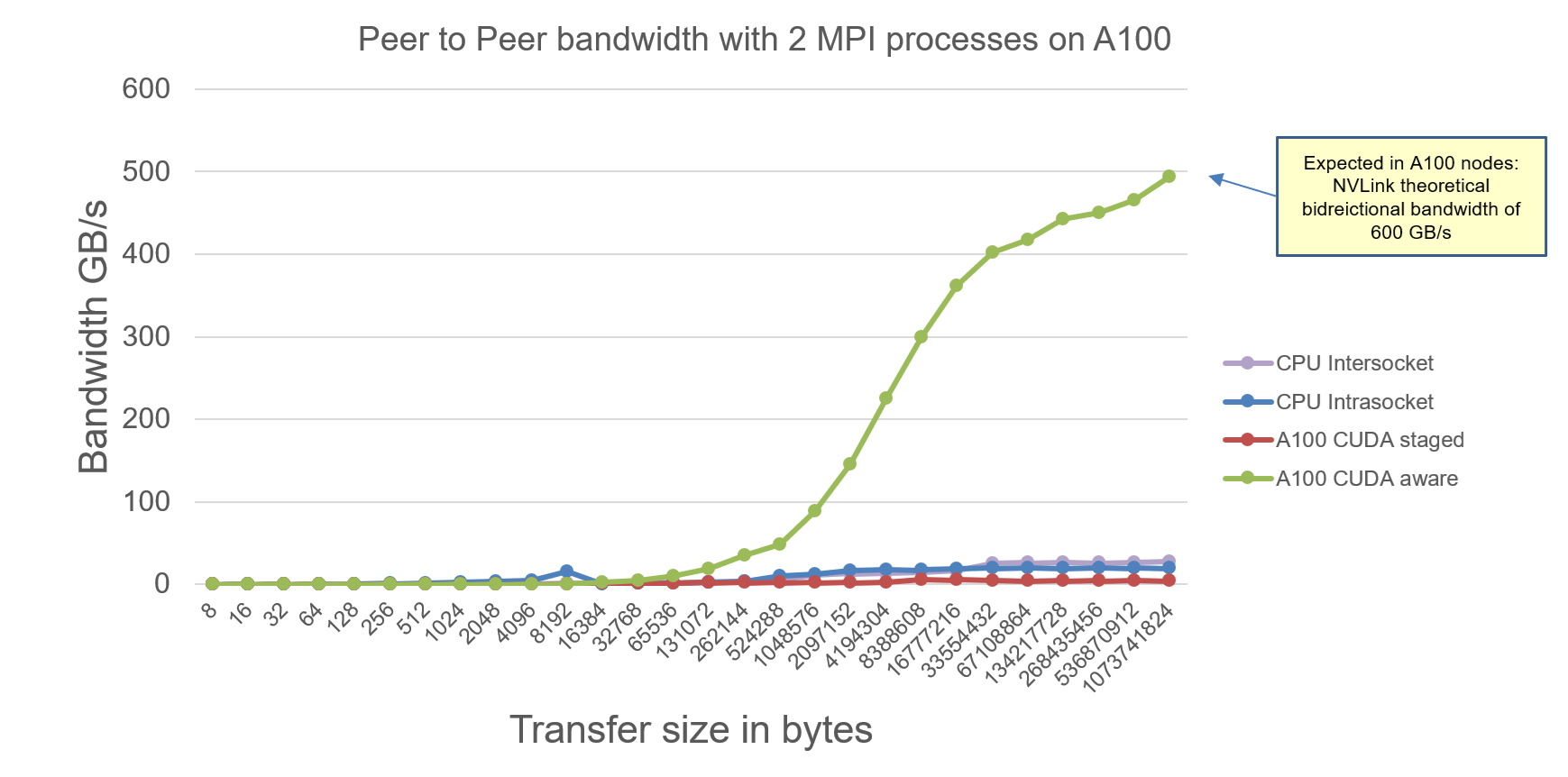
Explanation:
- We observe maximum effective bidirectional communication bandwidth of 500 GB/s between 2 A100 GPUs within one node. Less than theoretical bidirectional bandwidth of 600 GB/s.
- CUDA-staged-MPI is slower than pure-CPU communication. Expected because data is manually staged through CPU and then CPUs communicate bidirectionally.
The MPI Ping Ping Internode benchmarks on A100 node are as follows:
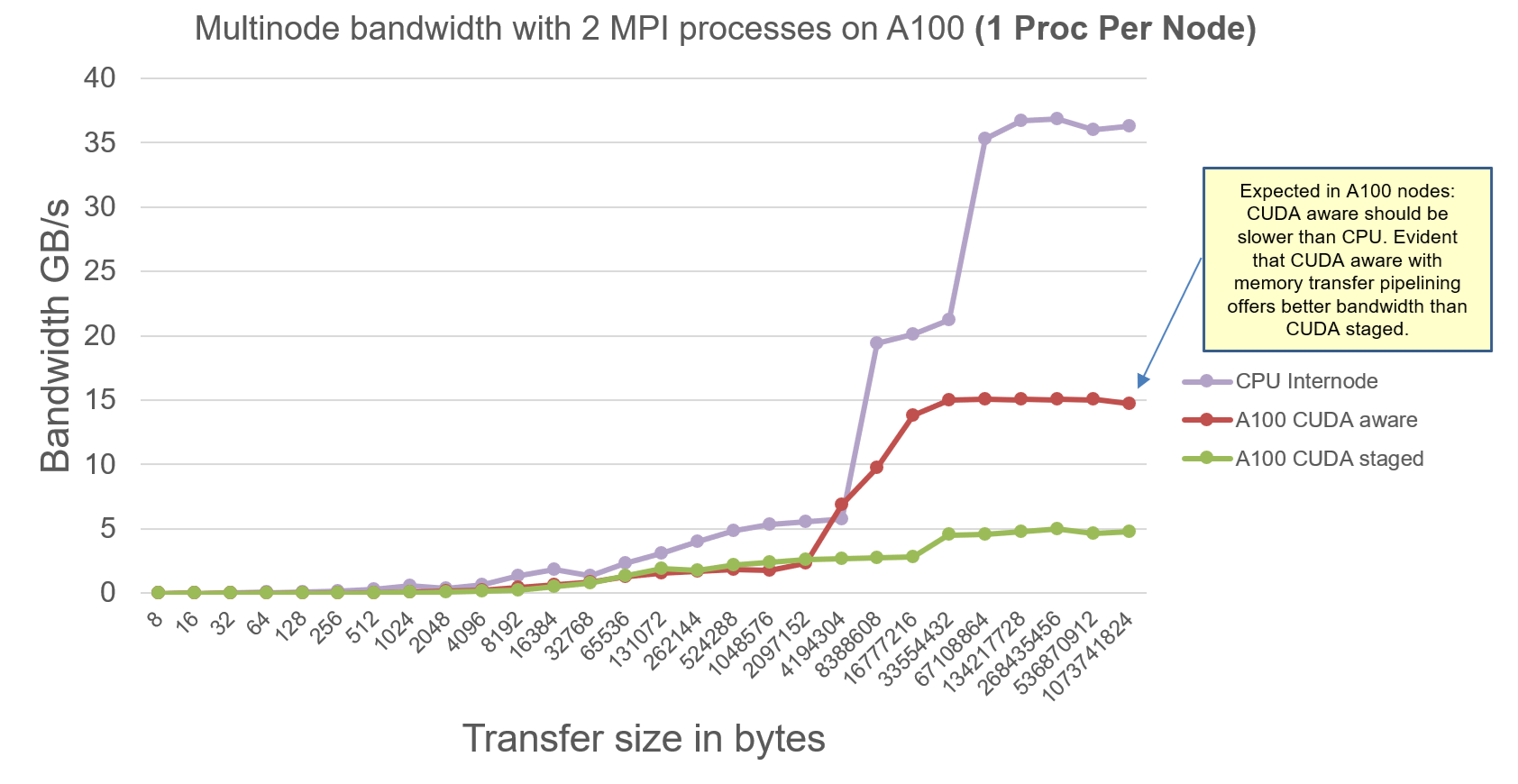
Explanation:
- CUDA-Aware-MPI program is slower than pure-CPU communication between 2 nodes. Since A100 does not have GPUDirect RDMA driver, MPI will internally stage the data through CPU while communicating. But because of message pipelining feature in CUDA-Aware-MPI, the observed effective bidirectional communication bandwidth is greater than CUDA-staged-MPI bandwidth.
- There are 2 x HDR200 between 2 A100 nodes, hence pure-CPU can achieve max effective bidirectional communication bandwidth of 35 GB/s. With more MPI processes communicating simultaneously, the observed max effective bandwidth will increase.
The MPI Ping Ping Intranode benchmarks on H100 node are as follows:
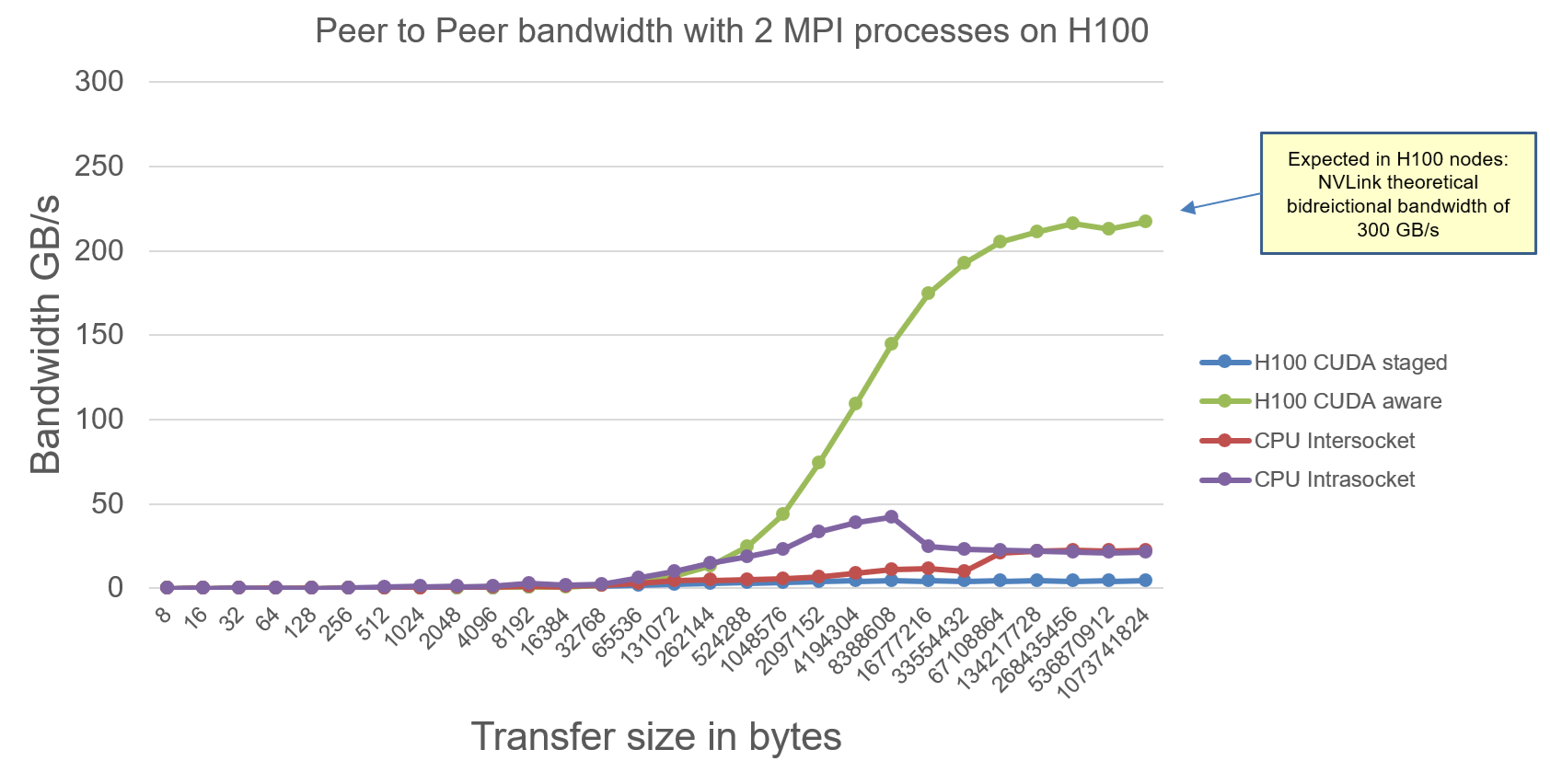
Explanation:
- CUDA-Aware-MPI max effective bidirectional communication bandwidth of 220 GB/s is well within theoretical bandwidth of 300 GB/s.
- CUDA-staged-MPI is as usual slower than pure-CPU. Expected because manually staging data to CPU and then CPUs communicating with each other is always slower.
The MPI Ping Ping Internode benchmarks on H100 node are as follows:
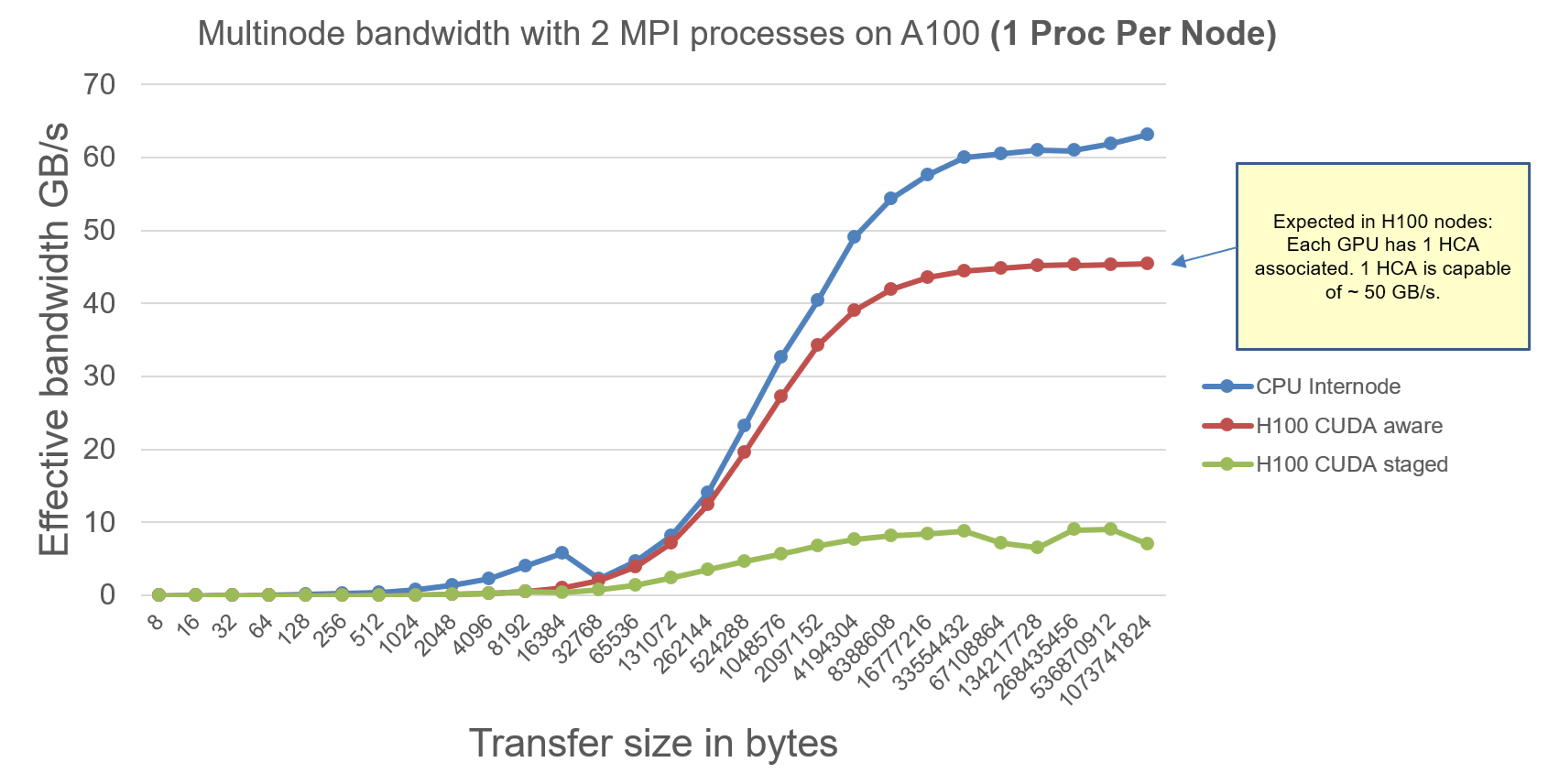
Explanation:
- H100 nodes have GPUDirect RDMA drivers. Hence MPI will not stage data through CPU while performing internode communication. CUDA-Aware-MPI is still slower than pure CPU because of the topology. CPU can access 2 HCA for communication, resulting in 100 GB/s limit. But there is only 1 HCA associated with 1 GPU, hence the theoretical limit of 1 HCA ~ 50 GB/s for GPU to GPU communication.
So far we have confirmed all the bottlenecks/limitations and tried to achieve near optimal effective communication bandwidth for all nodes. Next in this series, we take an application – 2D Poisson Solver with Jacobi Solver on GPUs. Ofcourse for the ghost cells exchange, we need MPI where GPUs perform the halo exchange. If you do not know about ghost cell exchange, do not worry. I will explain it briefly in the next post. =)
Thanks to Nvidia for letting me use their diagrams and symbols so that I could illustrate the node topology in a better way.
Thanks to NHR@FAU for letting me use their clusters for benchmarking.
For any questions regarding results or code, you can mail me at: aditya.ujeniya@fau.de