Hello readers,
This is the third part from the 4-part CUDA-Aware-MPI series.
In this blog series, we will use only NVIDIA GPGPUs and assume that the user know basics about CUDA-Aware-MPI from the official blogpost : https://developer.nvidia.com/blog/introduction-cuda-aware-mpi/[1]. Also, we assume that the reader knows about solving the 2D Poisson equation. For this, we are going to use a Jacobi solver on GPU.
Note: In CUDA-Aware-MPI, it is important to understand that MPI ranks only run on CPU. It is the MPI rank running on a particular CPU core that selects the GPU using:
cudaGetDeviceCount(&num_devices) //Gets number of GPU device per node.cudaSetDevice(rank % num_devices) //Particular MPI rank invoking this selects the GPU for execution
For the third post, we will focus on an application that requires communication. Solving 2D Poisson equation with Jacobi solver is a perfect application, that requires communication after each Jacobi solver iteration, to exchange ghost cells. This way, GPUs perform an iteration of Jacobi solver and then use CUDA-Aware-MPI to perform the halo exchange. Below is a demonstration of 2D domain decomposition, and the ghost cells exchange pattern:
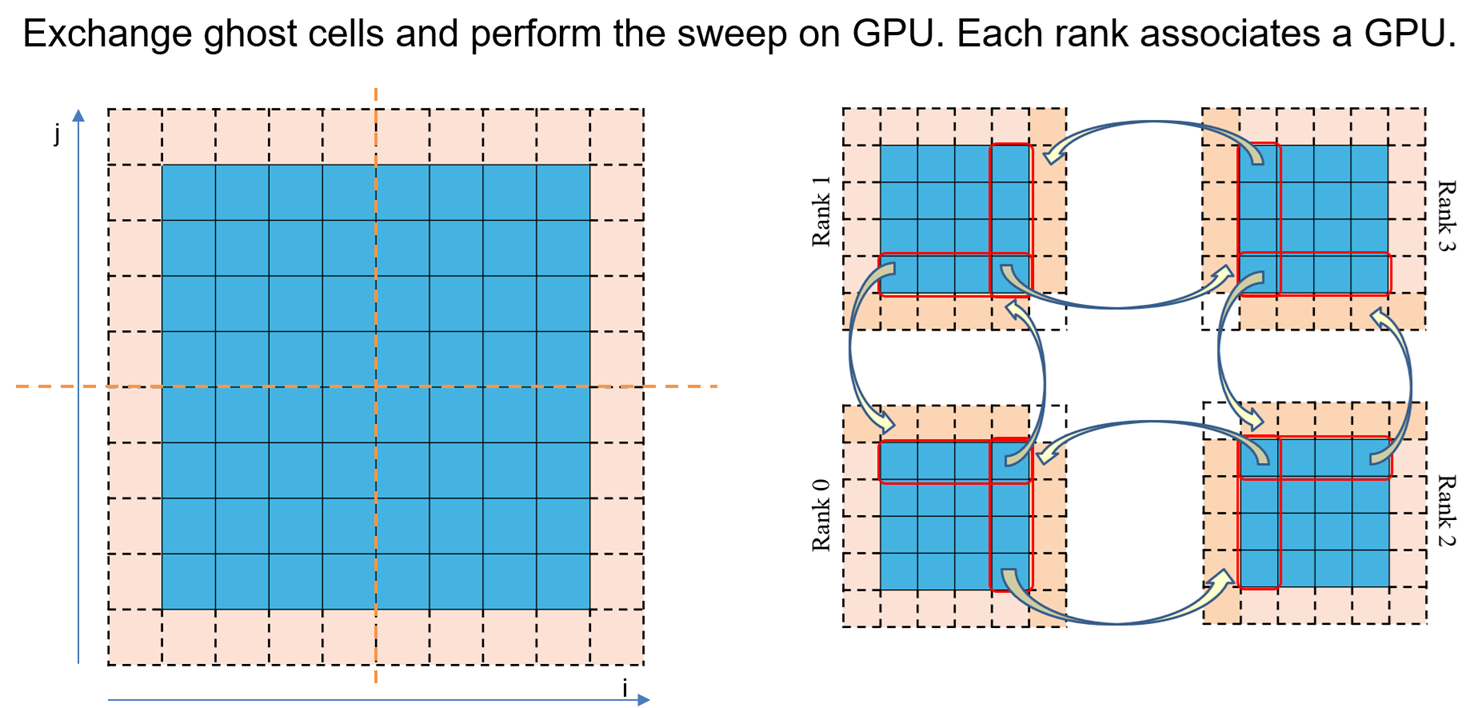
Explanation: Like 1D domain decomposition in the previous post, here we perform 2D domain decomposition such that each rank has to communicate with their left, right, top and bottom neighbors. So basically every GPU will perform a Jacobi sweep over its local domain and use CUDA-Aware-MPI to perform ghost cells exchange with their neighboring ranks. Note that we will be using:
MPI_Neighbour_Alltoallw();to exchange with neighbors. To the left and right neighbors we send non-contiguous/strided data and to the top and bottom, the rank sends contiguous data as shown below:

We use MPI_Type_vector() and MPI_Type_contiguous() derived datatypes and commit the address and datatypes to be sent to respective neighbors.
Let us scale this program with 2D domain decomposition. We will scale it with 8 nodes (1 MPI process and 1 GPU per node). The internode scaling for H100 nodes looks like this:
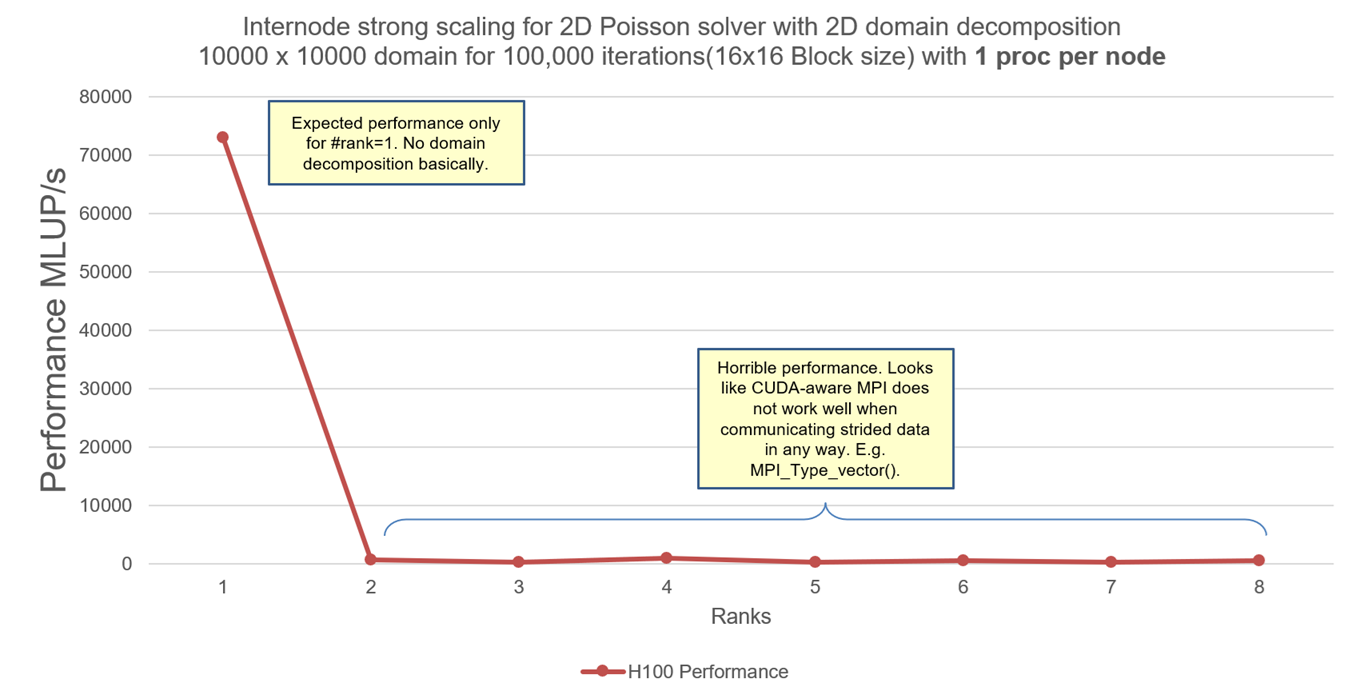
What ? Why ? The program with 2D domain decomposition does not scale at all. That’s sad. We investigate further using traces from NVIDIA-Nsight Systems and pinpoint where it goes wrong. From the traces as seen below, it shows that when GPUs want to communicate with their left and right neighbors, it has to pack the vector with strided data. So the packing of strided data is done in CPU memory. Basically, GPU stages/copies every strided element one by one to CPU memory, packs it there and then communication takes place. Also while unpacking, once CPUs finish communicating, unpacking of the strided elements happen one by one.

GPUs stages each and every strided element, then packing, then communicating, then unpacking and copying strided element by element into GPU address – all these results in drastic performance degradation. That is why we see such horrible performance when scaling the program with 2D domain decomposition. Note that H100 nodes have the GPUDirect RDMA driver installed and this staging of data is not related to absence of any driver.
So what can we do to alleviate this ? What measures can be taken to avoid staging ? The solution to this problem is explained in the last part of this 4-part series.
Thanks to NHR@FAU for letting me use their clusters for benchmarking.
For any questions regarding results or code, you can mail me at: aditya.ujeniya@fau.de