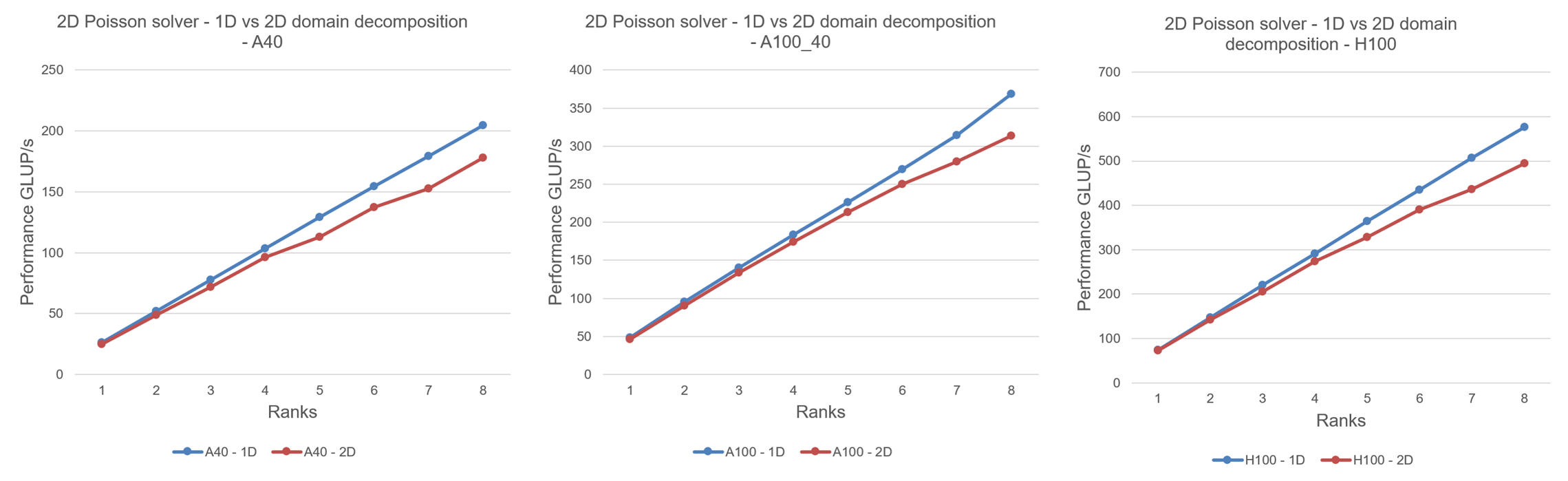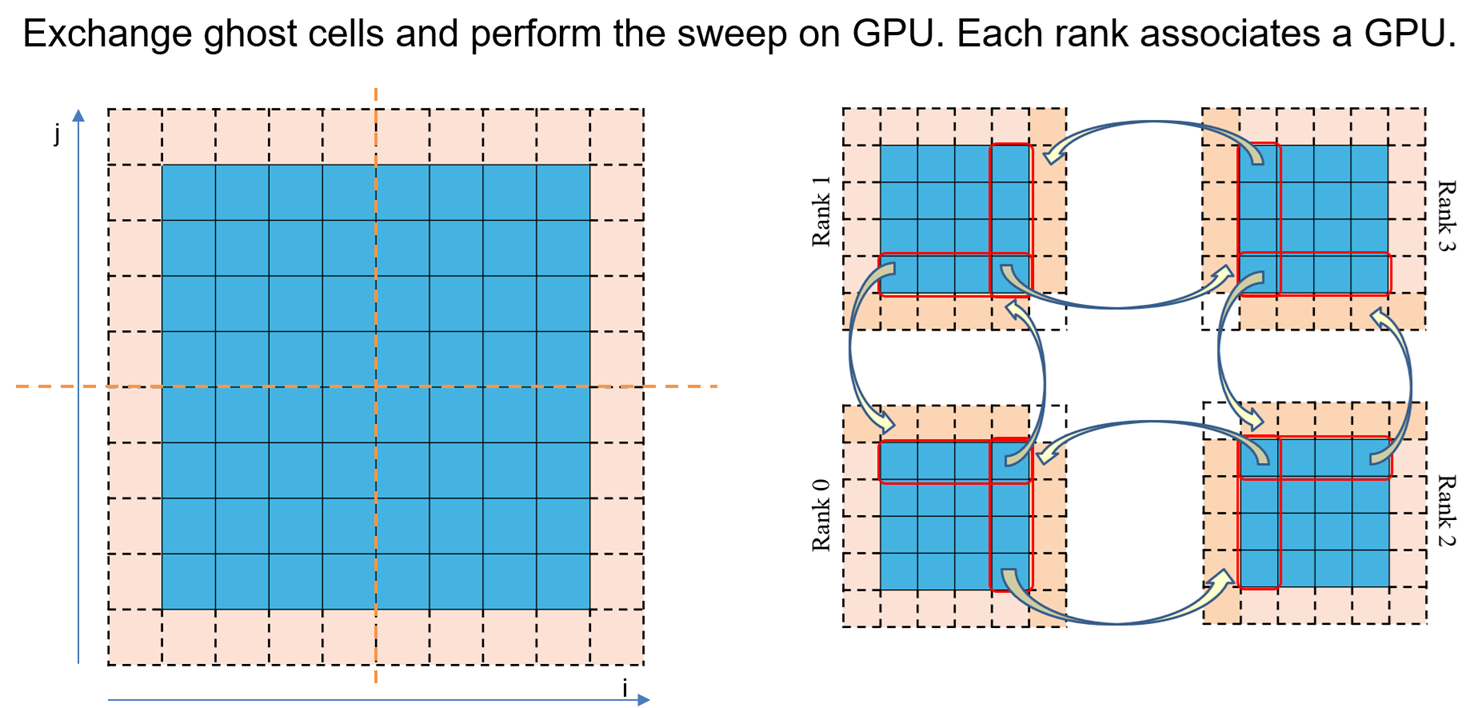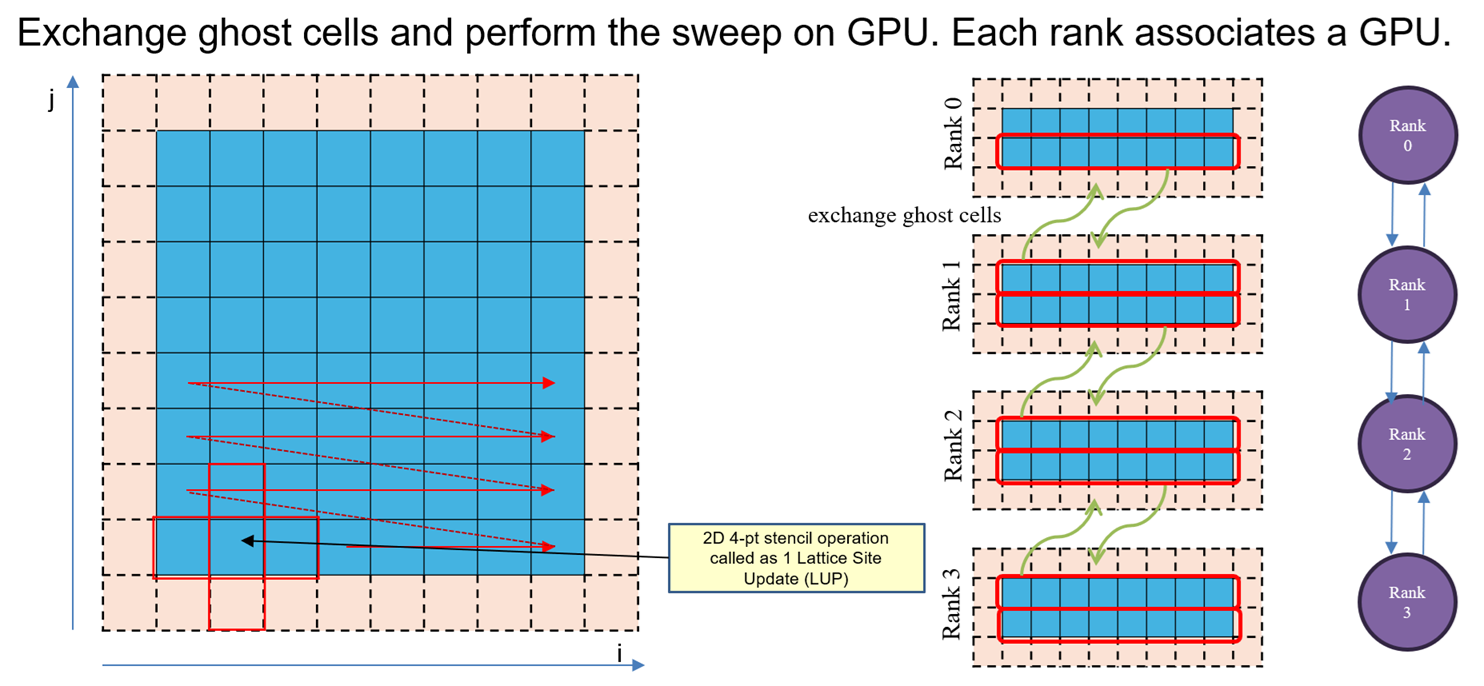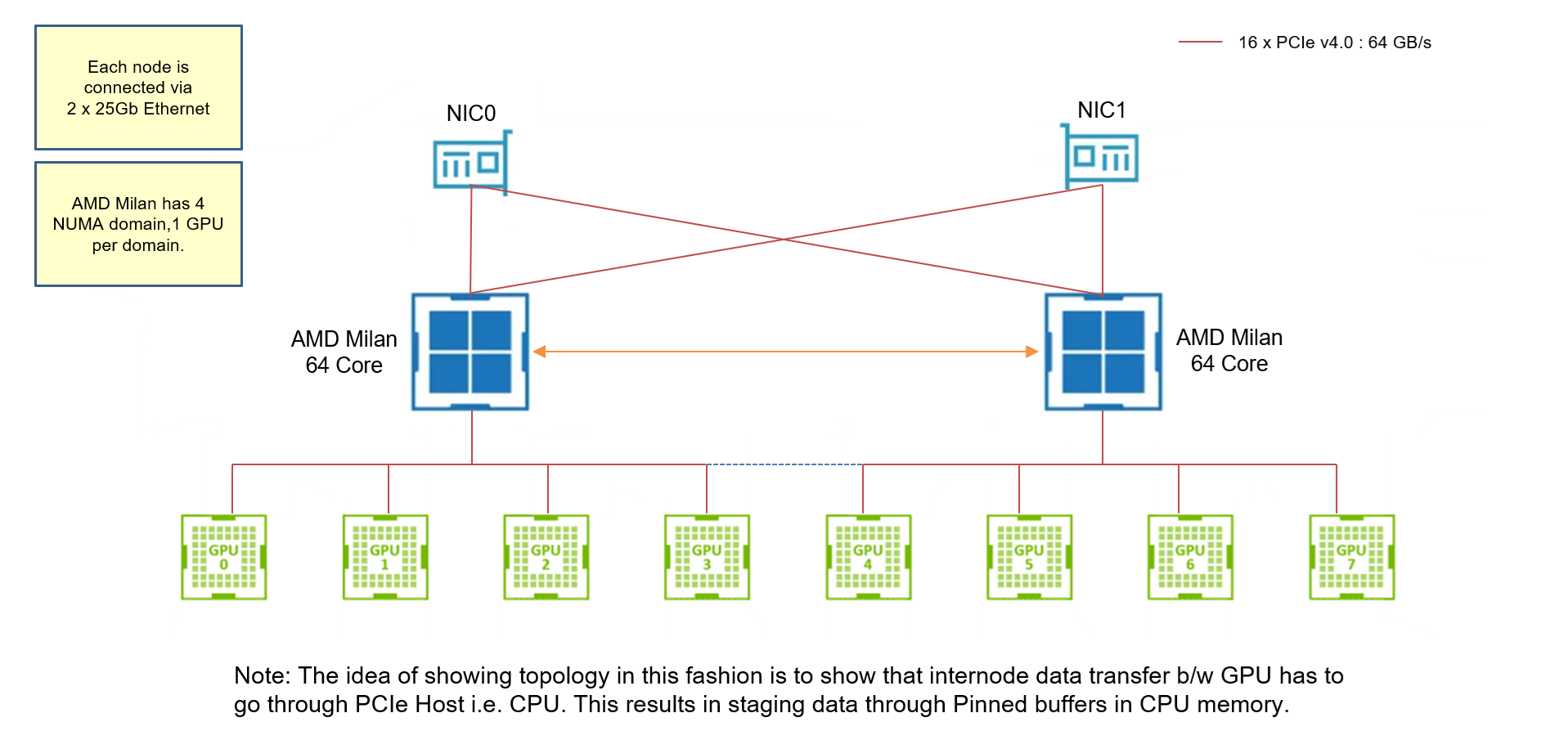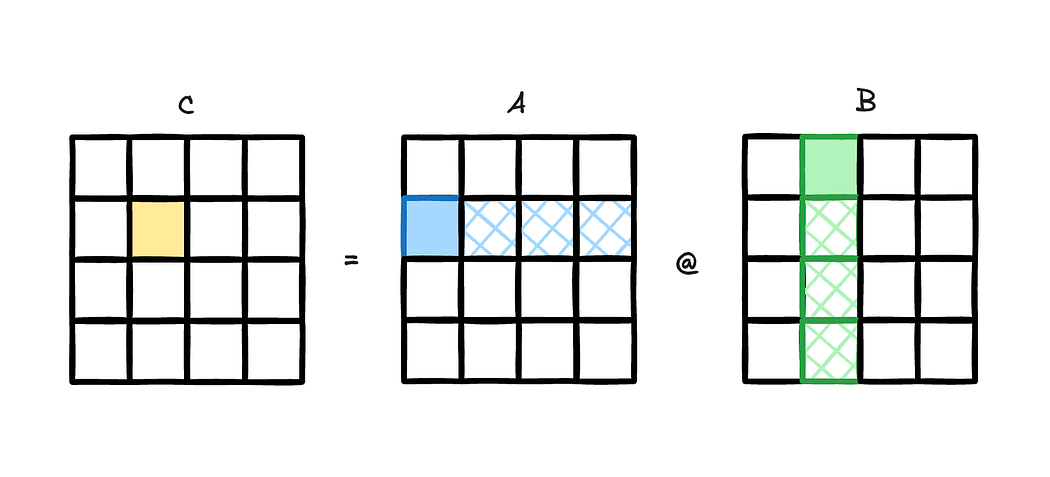
Hello readers, Today we talk about power and frequency characteristics of compute bound code, particularly SGEMM and DGEMM codes, but with a focus on different data initialization techniques. GEMMs are acronym for General Matrix Matrix multiplication. DGEMMs (Double-Precision GEMMs) involves 64 bit data (FP64 or double datatype) where it uses input matrix of FP64 datatype […]
Continue reading