Recently, we’ve frequently reached the I/O capacity of our RAID array during peak hours, meaning that increasingly often downloads were not limited by network speed, but by how fast our disks could deliver the data.
While we use a hardware RAID6 which does deliver pretty decent read speeds, we’re still using traditional magnetic hard drives, not SSDs. While these arrays easily deliver more than a Gigabyte per second when reading sequentially, this performance drops rapidly the more random the I/O gets, i.e. the more different files are requested at the same time. Of course, due to the nature of our FTP, which provides mirrors for a whole bunch of different projects, we do get a large amount of random I/O.
One solution to improve performance in this constellation is to use an additional cache on an SSD that caches the most frequently requested files or disk blocks. Most storage vendors implement something like that in their storage arrays nowadays, although it’s usually an optional and not exactly cheap feature – you usually pay a hefty license fee for that feature, and then you also have to buy prohibitively expensive SSDs from that vendor too to make any use of it. The better (and cheaper) alternative is to use a software solution to do the same thing. There are different implementations for SSD caching on Linux.
The SSD-caching implementation we chose to use was lvmcache. As the name suggests, lvmcache is integrated with the Linux Logical Volume Manager (LVM) that we use for managing the space on the big raid arrays anyways. The SSD is simply attached to a normal logical volume and then caches accesses to that volume by keeping track of which sectors are used most often and serving them from the cache-SSD.
Two basic modes are available: Write-back and Write-through. Write-Back writes blocks to the SSD-cache first and only syncs them to the disks some time later. While write-back has the advantage of increasing the write speed, it has the drawback that in this mode the SSD used for caching is vital – if it dies, the data on the disks would be left in an inconsistent and possible irrepairable state. To avoid data loss, some RAID level for the SSD would be required in this mode. However, we don’t really care about the write speed on the FTP – the only writes it sees are the updates of the mirrors, but those are few. More than 99% of all I/O is read requests from clients requesting some mirrored files. Because of that, we don’t really care about the write speed and instead use “write-through” mode. In this mode, all writes go to the underlying disk immediately, the SSD is only used for read caching. When the SSD dies, you lose the caching, but your data is still safe.
For testing, we borrowed a 1 TB Intel SSD. After one week of testing, we are impressed by the results. The following is a graph from our munin showing the utilization of the devices:
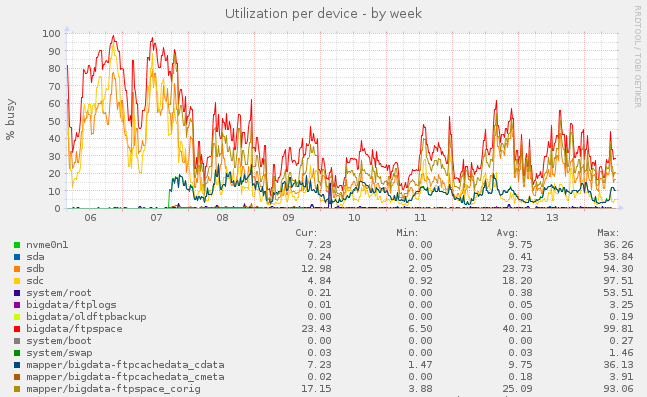
As you can see, we introduced the disk cache (nvme0n1) on the 7th. After about one day, the cache had filled up, and was now serving the magnitude of requests. As a result, the utilization on the disk arrays (sdb, sdc) dropped rapidly, from “pracitcally always 100%” to “30-50%” during peak hours.
If longterm performance is as good as these first test results suggest, we will permanently equip ftp.fau.de with a SSD for caching to allow faster downloads for you.