Intel hat mit den Nehalem-Prozessoren (Xeon X55xx bzw. Core i7) den Turbo Boost-Modus eingeführt, bei dem stark vereinfacht gesagt, einzelne Prozessorkerne automatisch höher takten können, wenn nur Teile des gesamten Prozessorchips genutzt werden und somit “Luft” bei Stromverbrauch, Spannung und Temperatur ist. Im LiMa-Cluster sind Intel Westmere Prozessoren mit 2,66 GHz (Intel Xeon X5650) verbaut. Diese Prozessoren erlaubt prinzipiell (bis zu) zwei Turbo Boost-Stufen (+2×133 MHz), auch dann wenn alle Kerne benutzt sind, und bis zu drei Turbo Boost-Stufen (+3×133 MHz), wenn maximal zwei der sechs Kerne eines Prozessorchips in Benutzung sind (vgl. Tabelle 2 im Intel Xeon Processor 5600 Series Specification Update vom September 2010). Das heißt unter günstigen Bedingungen laufen alle Prozessorkerne auch unter Volllast mit 2,93 GHz obwohl man eigentlich nur einen 2,66 GHz-Prozessor gekauft hat.
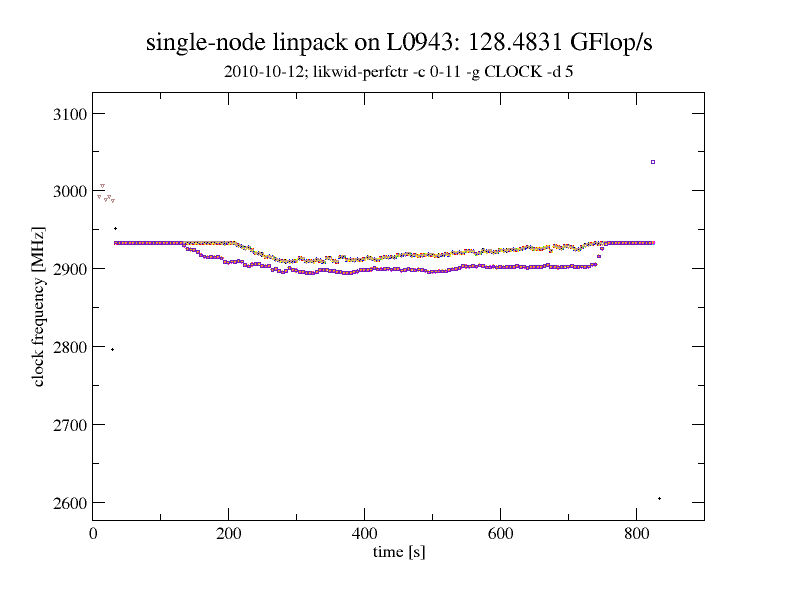
zeitlich aufgelöste Taktfrequenz beim LINPACK-Lauf auf einem guten Knoten
Dass annähernd zwei volle Turbo Boost-Stufen auch unter Vollast möglich sind, zeigt nebenstehende Grafik. Hierbei wurde mit einer Auflösung von 5 Sekunden die Taktfrequenz aller physikalischen Kerne im Knoten mittels LIKWID gemessen, während auf dem Knoten die multi-threaded LINPACK-Version aus Intel’s MKL lief. Bevor die LINPACK-Prozesse anlaufen, haben die Prozessorkerne aufgrund der ondemand-Frequenzeinstellung im Linux-Betriebssystem heruntergetaktet. Sobald “Last” generiert wird, takten die Prozessoren hoch. Wenn nach etlichen Sekunden die Prozessoren “durchgeheizt” sind, sinkt die Taktfrequenz nur leicht von 2,93 GHz auf rund 2,90 GHz. Am Ende des bzw. kurz nach dem LINPACK-Lauf takten die Prozessoren kurzfristig nochmals hoch, da zum einen die Last geringer geworden ist und somit die thermischen und elektrischen Grenzwerte für den Turbo Boost-Mode unterschritten sind, gleichzeitig der ondemand-Regler des Linux-Betriebssystems die Prozessoren aber noch nicht herunter getaktet hat. In der Grafik sind im wesentlichen nur zwei Kurven zu erkennen, obwohl es eigentlich 12 sind, da alle Kerne eines Sockels praktisch immer mit der gleichen Frequenz laufen.

zeitlich aufgelöste Taktfrequenz beim LINPACK-Lauf auf einem schlechten Knoten
Leider laufen jedoch nicht immer alle X5650-Prozessoren unter Volllast mit annähernd zwei Turbo Boost-Stufen, d.h. 2,93 GHz, wie die zweite Grafik zeigt. Hier takten die Rechenkerne über weite Teile des LINPACK-Laufs auf “nur” 2,7 GHz herunter, wodurch die gemessene Knotenleistung von rund 128,5 GFlop/s auf 120,5 GFlop/s sinkt — über 5% die man sicherlich auch in der einen oder anderen Form bei realen Anwendungen und nur nicht nur beim synthetischen LINPACK sieht.
Über die Ursachen der geringeren Übertaktung des zweiten Knotens kann derzeit nur spekuliert werden. Die Wärmeleitpaste zwischen den Prozessoren und den Kühlkörpern ist es jedenfalls nachweislich nicht. Ebenso ist es nicht das Netzteil oder die Position im Rack, da ein Umzug des Rechenknoten in ein anderes Enclosure in einem anderen Rack keine Besserung brachten. BIOS-Version, CMOS-Einstellung und CPU-Stepping sollten hoffentlich bei allen Knoten auch gleich sein. Dass zwei Prozessoren aus Hunderten eine Macke haben, mag ja durchaus sein, aber wie wahrscheinlich ist es, dass genau diese zwei Prozessoren dann auch noch im gleichen Rechner verbaut werden … Als wahrscheinlichste Ursache würde ich daher im Moment “Toleranzen” bei den Mainboards vermuten, die sich negativ auswirken. Aber Details wird NEC sicherlich im eigenen und unseren Interesse noch herausfinden …
Performance-Messtools wie LIKWID zahlen sich auf jeden Fall auch für die Abnahme von HPC-Clustern aus.
Hier nochmal sinngemäß die Befehle, die ich zur Messung verwendet habe: (LIKWID 2.0 ist dabei aufgrund des Daemon-Modus mindestens nötig und /dev/cpu/*/msr muss durch den aufrufenden User les- und schreibbar sein):
[shell]
/opt/likwid/2.0/bin/likwid-perfctr -c 0-11 -g CLOCK -d 5 | tee /tmp/clock-speed-`hostname`-`date +%Y%m%d-%H%M`.log > /dev/null &
sleep 15
env OMP_NUM_THREADS=12 taskset -c 0-11 /opt/intel/Compiler/11.1/073/mkl/benchmarks/linpack/xlinpack_xeon64 lininput_xeon64-50k
sleep 15
kill $! >& /dev/null
[/shell]
Da die Taktfrequenz eine abgeleitete Größe ist, kann es vorkommen, dass einzelne CPUs nan als Taktfrequenz liefern, wenn keine Instruktionen ausgeführt werden. Aber das ist natürlich nur dann der Fall, wenn auch kein Programm auf dem Prozessorkern läuft.