English Version
Dieser und die darauf folgenden Beiträge sollen einen Einblick in die Konzepte und Techniken des Identity Mangement Systems der FAU geben. Um die Serie etwas interessanter zu gestalten, werden die einzelnen Beiträge nicht streng logisch erscheinen. Die ersten zehn Beiträge behandeln also nicht das Konzept des Kerns. Vielmehr wird direkt im Anschluss an dieser zugegebenermaßen recht kurzen Übersicht die erste Anbindung eines Quellsystems beschrieben. Danach folgt ein Beitrag über die Anbindung eines Zielsystems, gefolgt von den grundlegenden Konzepten des Kerns, ein weiteres Quellsystem, …
Trotz dieser Sprünge wird versucht ohne große Wiederholungen und Vorwärtsverweise auszukommen. Mit etwas “Hintergrundwissen” sollten alle Beiträge eigenständig lesbar sein. Rückmeldungen sind natürlich willkommen!
Und jetzt viel Spaß beim Lesen.
Übersicht

IdM Lebenszyklus
Eine der Hauptgründe für die Einführung eines Identity Management Systems (IdMS) ist die zentrale Provisionierung und Deprovisionierung von Konten unterschiedlicher Dienste für Personen einer Organisation. Tritt eine neue Person in die Organisation ein, sollen möglichst sofort alle benötigten Ressourcen, welche zur Erledigung der zugedachten Aufgaben nötig sind, bereitstehen. Ändert sich das Aufgabengebiet einer Person, soll die Bereitstellung der Ressourcen angepasst werden. Verlässt eine Person schließlich die Organisation, sollen alle zugeteilten Ressourcen möglichst sofort entzogen werden.
Neben diesen grundlegenden Änderungen, besteht jedoch auch der Wunsch nach einer dauerhaften Aktualisierung von provisionierten Attributen. Das wohl bekannteste Beispiel eines solchen Attributs ist das Passwort. Aber auch Änderungen persönlicher Daten, wie z.B. Titel oder Kontaktadresse, sollen zeitnah in alle angeschlossenen Systeme, welche das entsprechende Attribut verwenden, aktualisiert werden.
Um diese Aufgaben erfüllen zu können, sind jedoch einige Vorarbeiten nötig. Die
genannten Vorgänge
- neue Person tritt in die Organisation ein
- Aufgabengebiet einer Person ändert sich
- Attribute einer Person ändern sich
- Person verlässt die Organisation
müssen erkannt und entsprechend verarbeitet werden. Besitzt die Organisation nur ein System zur Verwaltung von Angehörigen, kann diese Erkennung durch eine lesende Anbindung erledigt werden.
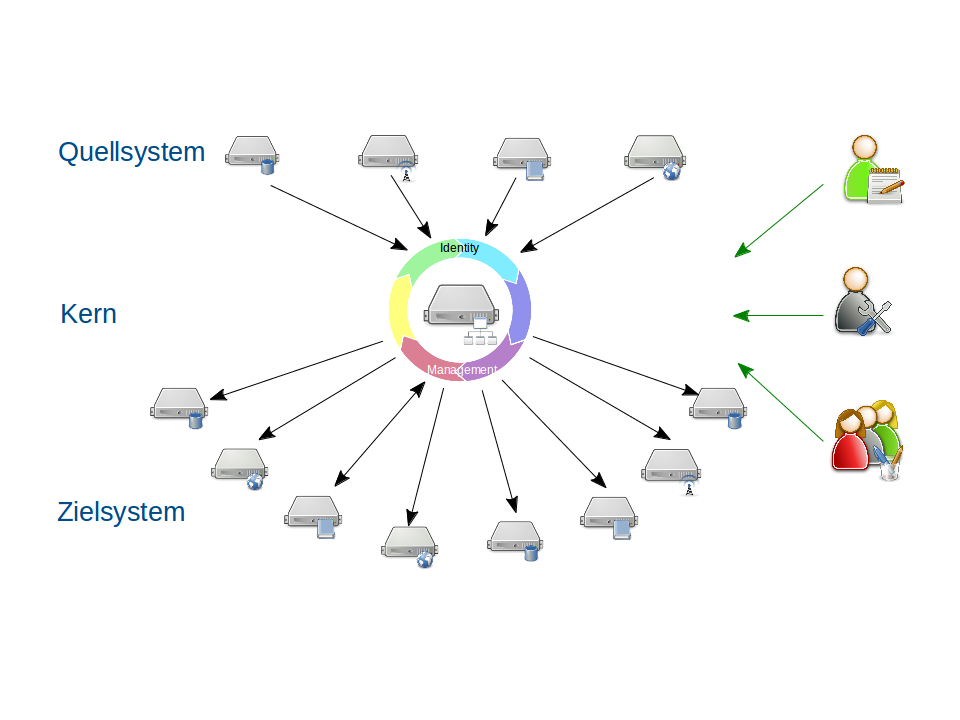
IdM Übersicht
Kommen zwei oder mehrere Systeme zum Einsatz, kommt eine weitere Aufgabe für das IdMS dazu: die Zusammenführung von Einträgen aus verschiedenen Systemen, welche zur gleichen realen Person gehören. Im vorhandenen Fall einer Universität, können als ein Beispiel die Verwaltungssysteme von Mitarbeitern und Studierenden herangezogen werden. Studierende können während ihres Studiums als wissenschaftliche Hilfskräfte tätig sein oder nach dem Abschluss, teilweise mit einer zeitlichen Lücke, als Mitarbeiter anfangen.
Dennoch beginnt alles mit dem Auslesen dieser Systeme, den sogenannten Quellsystemen. Die Konsolidierung der ausgelesenen Daten und darauf aufbauend die Berechnung von zuzuweisenden Dienstleistungen ist der nächste Schritt. Die so ermittelten Dienstleistungen müssen schließlich noch als Konten in die entsprechenden Systeme, den sogenannten Zielsystemen, provisioniert werden. Die Abbildung stellt die einzelnen Schritten schematisch dar.
Identity Management at the FAU – Overview (Part 1)
This and the following post should give an insight to the concept and techniques of the identity management system of the FAU .
To make this series more interesting, the indivudual posts will not appear strictly logical. The first ten posts will therefore not cover the core of the concept. Rather there will be following directly to this, admittedly quite short overview the first connection of a source system displayed. Afterwards a post about the connection of a target system will continue the series, followed by essential concept of the core, another source system, …
Despite of these jumps there should be no repetitions or any forward references. With a little “background knowledge” it should be possible to read the posts individually. Feedback is of course welcomed!
And now: have fun reading.
Overview
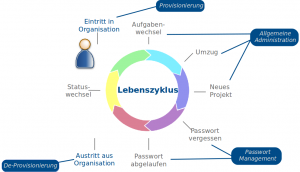
- IdM Life Cycle
One of the main reasons for the introduction of an identity management system (IdMS) is the central provisioning and deprovisioning of accounts of different services for persons of an organisation. If a person joins the organisation, then there should be preferably every resources, which are needed for the intended task, directly available. If the field of action changes for a person, the provision of resources has to be adjusted. If a Person leaves the organisation, every assigned resource has to be taken back immediately.
Beside these fundamental changes, there is also the wish for a lasting update of provisioned attributes. The best known example of such an attribute is the password. But also changes of personal data, such as title or contact address, should be updated immediately in every connected system.
To complete these tasks however some preliminary work is needed. The said actions
- new person enters the organisation
- field of action of a person changes
- attribute of a person changes
- person leaves organisation
need to be identified and be used accordingly. If the organisation only has a system for the administration of members, this cognition can be completed with a reading connection.
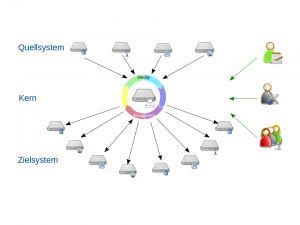
- IdM Overview
If there are two or more systems used, there will be another task for IdMS: the connection of entries from different systems which belong zu the same real person. In the existing case of a university, the adminstration systems of employees and students can be used as an example. Students can be working as student assistants during their studies or after that, sometimes with a short time gap, start to work as an employee.
However, everything starts with the reading of these systems, the so called source system. The consolidation of the read data and on this data build calculations of referable services is the next step. Eventually the so determined services have to be provisioned into an according system. The illustration shows schematically the individual steps.