Hintergrund
Im November 2006 startete das Projekt zum Aufbau einer zentralen Identity Management-Infrastruktur mit der Zielsetzung, eine Grundlage für die effiziente Nutzung der universitären IT-Dienste bereitzustellen (siehe Projektleitdokument vom 20.12.2006). Die damals festgelegten strategischen Ziele haben bis heute Bestand:
- Bewältigung der steigenden Verwaltungsanforderungen
- Vermeidung duplizierter Datenbestände
- Erhöhung der Benutzerfreundlichkeit
- Entlastung der Sachbearbeiter und Administratoren
- Erhöhung der Datenqualität und Validität
- Erhöhung der Datensicherheit
Hinzu kam im Laufe des Projekts der Aspekt der Systemintegration, der durch ein IdMS nicht nur gefördert, sondern erst grundlegen ermöglicht wird.
Am 8. Oktober 2008 gingen erste Teile “hinter den Kulissen” in den produktiven Betrieb. Seitdem wurden auf dieser Basis eine Vielzahl von Erweiterungen entwickelt, welche das heutige IdMS letztendlich ausmachen. Das Grundkonzept blieb im Kern erhalten.
Alle folgenden Ausführungen beziehen sich auf den aktuellen Stand des Systems.
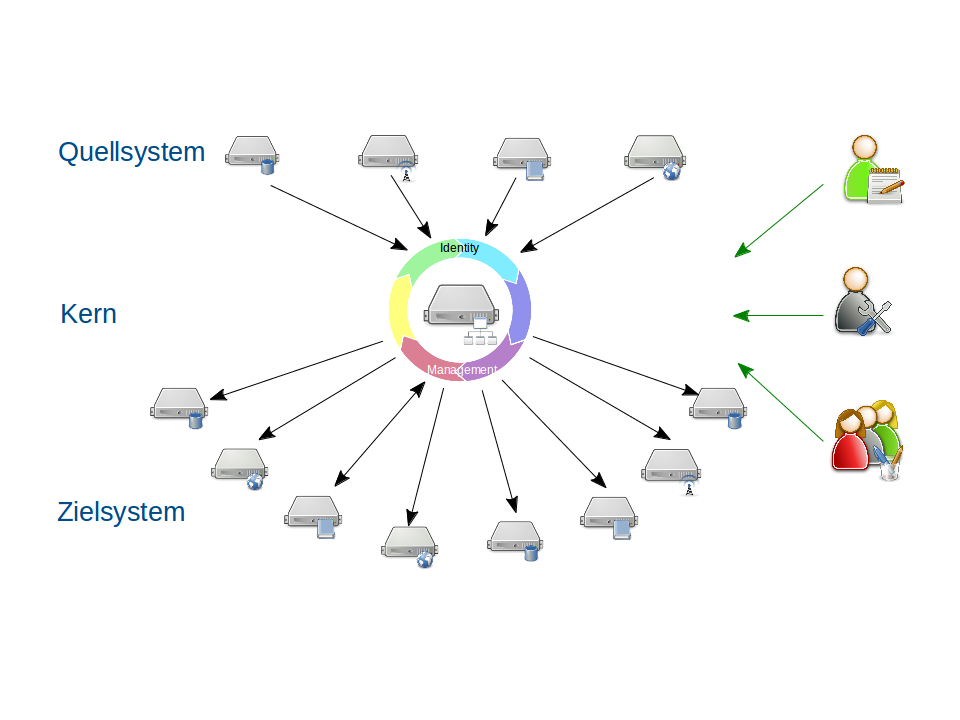
Quellsysteme
Als Quellsysteme werden Systeme bezeichnet, aus welchem das IdMS Daten liest. Die Quellsysteme des IdMS können grob in folgende Kategorien unterteilt werden:
- Personenverwaltungssysteme
- Strukturverwaltungssysteme
- Sonstige Systeme
Aktuell sind folgende Personenverwaltungssysteme angebunden:
- Stammdatensystem für Studierende HIS SOS
- Personalverwaltungssystem VIVA
- Indirekt über das IdM-nahe Personenverwaltungssystem für “Sonstige” (Yet Another AFFiliation, kurz yaaff) als Qualitätssicherungsschicht:
- Informationssystem UnivIS
- Promovierendenverwaltung docDaten
- Personenverwaltungssystem FAU Busan
- Sonstigenverwaltung RRZE
Der einzige Vertreter der Kategorie Strukturverwaltungssysteme ist die zentrale Anwendung zur Pflege der Organisationsstruktur FAU.ORG.
Vertreter der Kategorie “Sonstige Systeme” sind u.a. Systeme welche die Datenhoheit für mindestens ein Attribut besitzen. Zum Beispiel werden die offiziellen Mailadressen nicht im IdMS erzeugt bzw. festgelegt, sondern aus dem System zur Reservierung von Mailadressen abgefragt.
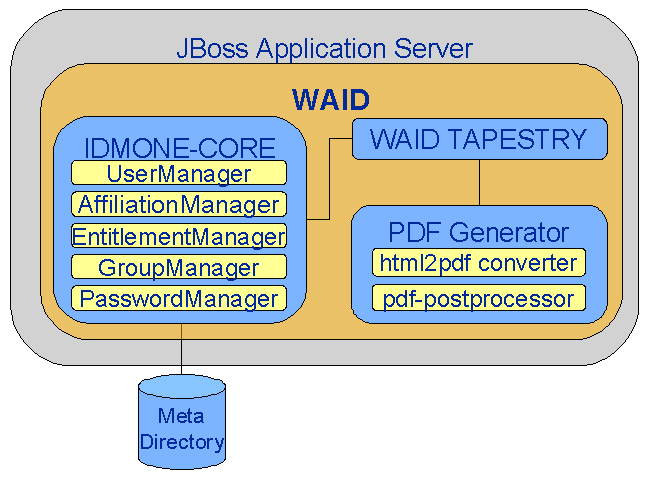
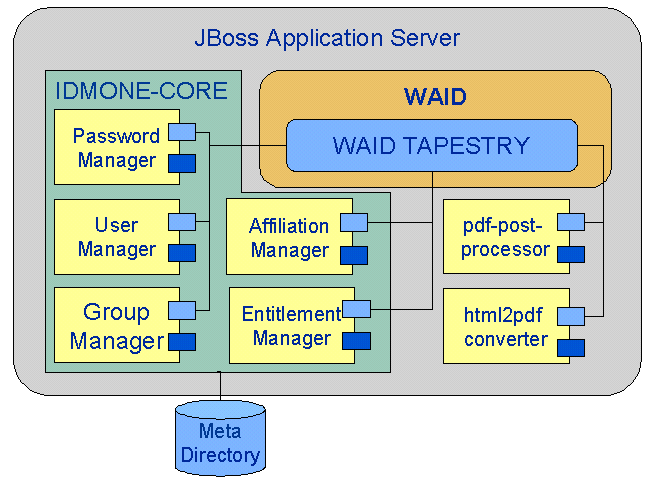
Kern
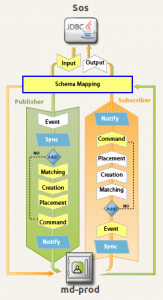
Der Kern des IdMS besteht aus einer Vielzahl von einzelnen Modulen. Während ein Teil der Module die korrekte Zusammenführung von Personeneinträgen aus unterschiedlichen Quellsystemen übernimmt, berechnet ein anderer Teil die ableitbaren Dienstleistungen. Allen gemein ist das zugrundeliegende Meta-Directory, also die IdMS gespeicherten Daten.
Änderungen in Quellsystemen sollen möglichst zeitnah aufbereitet und in alle betroffenen Systeme synchronisiert werden. Darunter fallen auch Aktionen der Anwender in den Web-Anwendungen; allen voran das Setzen eines neuen Passworts. Die Auswirkungen reichen von einfachen Wertänderungen in einem Attribut bis hin zur kompletten Neuanlage oder Löschung eines Kontos.
Zielsysteme
Als Zielsysteme werden Systeme bezeichnet, in welche das IdMS Daten schreibt. Aktuell sind folgende Zielsysteme angebunden:
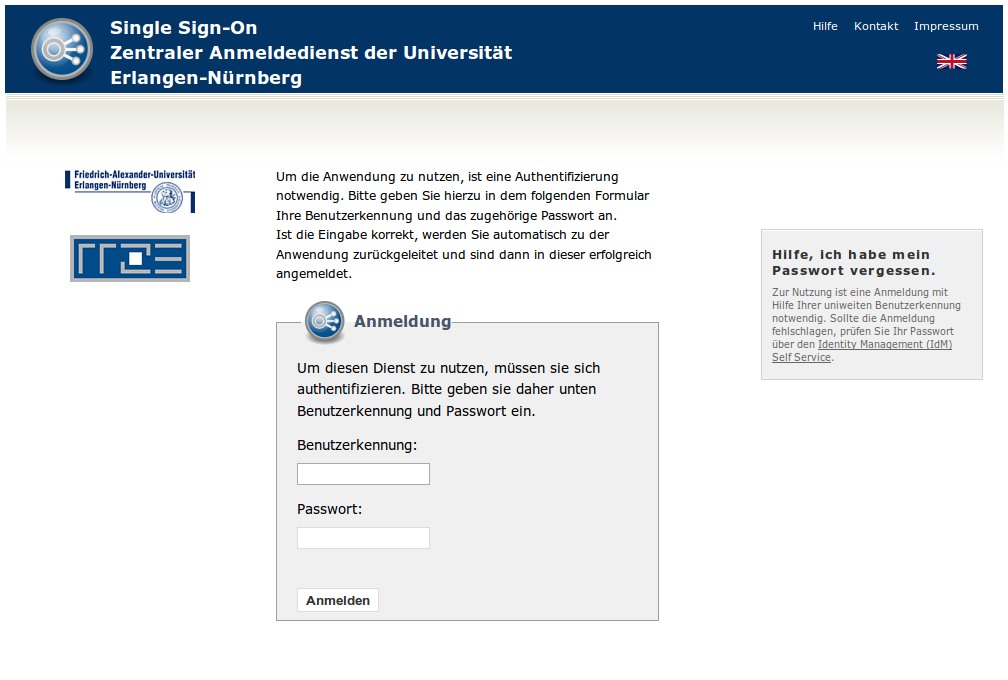
- Zentraler Anmeldedienst der Universität Erlangen-Nürnberg (Single Sign-On)
- Studierendenverwaltung HIS SOS
- mein campus
- Promovierendenverwaltung docDaten
- Mail-Adressen-Reservierungssystem der FAU
- Mail-Relay-System der FAU
- Mailinglistenverwaltung Mailman
- FAUmail (Dovecot)
- Windows Exchange
- Novell Groupwise
- WLAN eduroam
- Windows Active Directory (AD)
- Novell Directory Services (NDS)
- Versionskontrollsysteme via gvcsadmin
- Web-Anwendung FAU.ORG
- Kartenproduktionssystem der FAUcard
- Bibliothekssystem SISIS
- “Alte” RRZE-Benutzerverwaltung
- Zutrittskontrollsystem Siport (im Aufbau)
- Forschungsdatenbank (im Aufbau)
Frontends
Als Frontends werden Systeme bezeichnet die beispielsweise im Rahmen einer Webanwendung Zugriff auf bestimmte Daten und Funktionen des IdMS bieten.
IdM-Portal
Das IdM-Portal gliedert sich derzeit in die Bereiche “Self Service” und “Anfragen/Aufgaben”.
Der Self Service ermöglicht den im IdMS verwalteten Person die Einsicht von gespeicherten persönlichen Daten zum Zwecke der Datenschutzselbstauskunft. Desweiteren kann der Benutzer den Status der verfügbaren Dienstleistungen einsehen und Aktionen zur Konto- und Diensteverwaltung durchführen.
Der Bereich Anfragen/Aufgaben ermöglicht es, u.a. auch langlaufende Prozesse mit mehreren Beteiligten Personen einfach zu verwalten.
Administration
Die Administrationsfunktion im IdMS bietet Mitarbeitern des RRZE und der FAU mit Aufgaben im IdM-Umfeld erweiterten Zugriff auf die zur Durchführung nötigen Daten.
Dazu gehören z.B. die Mitarbeiter der Service-Theken, die so Benutzern bei Problemen mit ihrem IdM-Zugang oder einzelnen Dienstleistungen auf Anfrage Hilfestellung geben können. Die häufigsten Fälle sind das Wiederherstellen vergessener Passwörter und die Hilfe bei der Konfiguration einzelner Dienstleistungen.
Identitiy Management at the FAU – Background and Current State (Part 3)
Background
In November 2006 the project started to develop a central Identity Management Infrastructure with the aim to provide a basis for the efficient usage of university based IT services (see further Projektleitdokument from 20.12.2006). The then defined strategic aims are still existing today:
- Management of increasing administrative demands
- To avoid duplicated data storage
- Improvement of user friendliness
- Relief for employees and administrators
- Improvement of data quality and validity
- Improvement of data security
During the course of the project the aspect of system integration was added which can not only be advanced through an IdMS, but be enabled through it in the first place.
On 8. October 2008 first parts “behind the scenes” went into the productive area. Since then multiple enhancements were developed on this base, which in the end make today’s IdMS. The basis concept remains unchanged.
All the following implementations are related to the current state of the system.
Source System
Systems are called source systems which are reading data from the IdMS. The source systems of the IdMS can roughly be separated in the following categories:
- Personal administration systems
- Structural administration systems
- Other systems
At the moment the following personal administration systems are included:
- Master data systems for students HIS SOS
- Personal administration system VIVA
- Indirectly via the near IdM personal administration system for “others” (Yet Another AFFiliation, short yaaff) as a layer for quality management:
- Information system UnivIS
- PhD-students administration docDaten
- Personal administration system FAU Busan
- Other management RRZE
The only representative of the category structural administration system is the central application to maintain the organizational structure FAU.ORG.
Representatives of the category “other systems” are for example systems which have data sovereignty for at least one attribute. For example official mail addresses are not created or defined in the IdMS but are questioned from the system for the reservation of mail addresses.
Core
The core of the IdMS consists of a multitude of single modules. Whereas a part of the modules takes the correct compilation of personal entries from different source systems, another part computes deducible services. They all have the underlying meta directory in common, thus the in IdMS saved data.
Changes in the source systems should be quickly prepared and synchronized with all the affected systems. These include actions of the users in web applications; especially the setting of a new password. The consequences range from simple value changes in one attribute to the complete new generation or deletion of an account.
Target systems
Systems are called target systems in which the IdMS writes its data. At the moment the following target systems are included:
- Central Sign-ON Service of the University Erlangen-Nuremberg (Single Sign-On)
- Student management HIS SOS
- mein campus
- PhD-student management docDaten
- Mail Addresses Reservation System of the FAU
- Mail Relay System of the FAU
- Mailing list managment Mailman
- FAUmail (Dovecot)
- Windows Exchange
- Novell Groupwise
- WLAN eduroam
- Windows Active Directory (AD)
- Novell Directory Services (NDS)
- Version control system via gvcsadmin
- Web Application FAU.ORG
- Card production system of the FAUcard
- Library system SISIS
- “Old” RRZE user management
- Access control system Siport (in development)
- Researchdatabase (in development)
Front end
Systems are called front end in the frame of a web application which provides access to certain data and function of the IdMS.
IdM-Portal
At the moment the IdM-Portal is structured in the areas “Self Service” and “Requests/Tasks”.
The Self Service offers the persons who are managed in the IdMS to see the saved personal data in order of data privacy self information. Furthermore the user can see the status of the available services and can perform actions for account and service management.
The area requests/tasks offers, among others, to easily manage even long-term processes with multiple participants.
Administration
The administration function in the IdMS offers the RRZE and FAU employees with tasks within the IdM environment an extended access to the data which are needed for the implementation.
It includes e.g. the employees of the service counters who can therefore help users with problems according to their IdM account or individual services on demand. The most frequent cases are the restoration of forgotten passwords and the help with the configuration of individual services.