Quellsysteme
Wenn im Identity Management (IdM) Bereich von Quellsystemen die Rede ist, denkt man häufig sofort an Personenverwaltungen. Die Bereitstellung von Informationen zu Personen ist sicherlich die bedeutendste und außenwirksamste Variante. Quellsysteme eines IdMS können jedoch ganz unterschiedlicher Natur sein. U.a. gehören auch die Lieferung von Daten zur Organisationsstruktur, Mailadressen oder Funktionen in die Kategorie der Quellsysteme. Allen gemeinsam ist, dass sie Informationen bereitstellen, die von anderen, meist mehreren, Systemen genutzt werden.
HIS SOS
Eines der ersten angebundenen Systeme des IdMS an der FAU war die Studierendenverwaltung vertreten durch HIS-SOS. Die Bereitstellung der Daten besteht im Wesentlichen aus zwei Datenbank-Views:
• idm student • idm stg
idm student enthält alle erforderlichen Informationen zur Person der Studierenden. Analog enthält idm stg alle erforderlichen Informationen zum Studium. Verbunden sind beide Views durch die Matrikelnummer, welche gleichzeitig in beiden Fällen den Primärschlüssel für die IdM-Anbindung darstellt.
Zum Auslesen der beiden Views kommt der JDBC-Treiber von Novells Identity Manager zum Einsatz. Um den Aufwand auf Seiten der Betreiber der Studierendenverwaltung gering zu halten, kommt keine Triggertabelle zum Einsatz. Der Vorteil einer Triggertabelle wäre die direkte Bereitstellung aller Änderungen. Der Treiber kann durch ein Lesen dieser Tabelle erkennen, ob Änderungen vorliegen. Falls ja kann er je nach Art der Triggertabelle alle Informationen zur vorliegenden Änderung direkt auslesen, oder nur die betroffenen Datensätze aus den Views holen. Ohne Triggertabelle muss der Treiber die Änderungen durch einen Vergleich mit seiner internen Kopie der Daten selbst erkennen. Liegen keine Änderungen vor, wäre in der Triggertabelle kein Eintrag und die Arbeit des Treibers wäre erledigt; ohne Triggertabelle müssen immer alle Einträge überprüft werden. Aktuell benötigt der Treiber für diese Aufgabe etwas unter 5 Minuten (inkl. SELECT) für beide Views mit je über 60.000 Einträgen. Bei einem Polling-Intervall von aktuell 5 Minuten ist der Treiber in der aktuellen Konfiguration daher am Limit.
Die Synchronisierung der beiden Views in Richtung IdMS wird in den folgenden Abschnitten näher erläutert. Dabei werden grundlegende Kenntnisse des Treiber-Konzeptes von Novell Identity Manager vorausgesetzt. Eine schematische Übersicht liefert Abbildung 3.1.
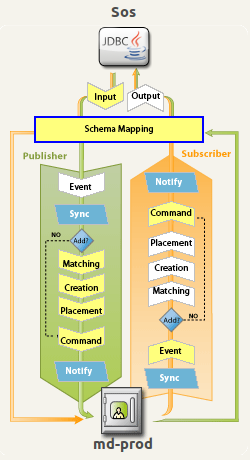
Abbildung 3.1: Treiber Sos
View idm student
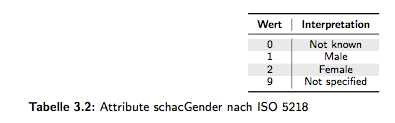
Tabelle 3.3 zeigt das Schema-Mapping und die Filter-Einstellung zwischen dem View idm student und der Objektklasse User (aka inetOrgPerson) im Meta-Directory (MD). In der ”Input Transformation Policy“ wird das Attribut Geschlecht (geschl) anhand der in Tabelle 3.1 aufgeführten Abbildung umgesetzt. Wie in Tabelle 3.3 ersichtlich wird im MD das Attribut schacGender des SCHema for ACademia 2 (SCHAC) verwendet, welches den Standard ISO 5218 einsetzt. Demzufolge werden die Werte wie in Tabelle 3.2 dargestellt interpretiert.

Die ”Matching Policy“ besteht im Wesentlichen aus zwei Teilen. Grundsätzlich wird versucht einen bereits im MD existierenden Personeneintrag zu finden und mit dem neuen Eintrag aus SOS zu verbinden. Ist ein Matching erfolgreich, werden die darauffolgenden Versuche unterlassen; die Reihenfolge ist also entscheidend.
Den ersten Versuch könnte man als ”Standard-Matching“ bezeichnen. Ein bereits aus SOS synchronisierter Eintrag soll damit wiedergefunden werden. Wurde der Eintrag in SOS entfernt und wieder mit der gleichen Matrikelnummer angelegt oder hat der Treiber aus anderen Gründen seine Assoziation (DirXML-Association) verloren, soll diese wiederhergestellt werden. Um dies zu gewährleisten wird ein Matching auf Basis des Primärschlüssels der Anbindung, in diesem Fall also die Matrikelnummer, durchgeführt. Hier wird die Matrikelnummer der Reihe nach in folgenden Attributen gesucht:
1. Attribut fauStudPK
2. Attribut fauStudPKOld
HIS SOS
Die Suche im Attribut fauStudPK stellt sicher, dass keine zwei Einträge mit der gleichen Matrikelnummer im MD existieren bzw. erzeugt werden. Die Suche im Attribut fauStudPKOld soll bereits exmatrikulierte Studierendeneinträge finden. Werden Einträge im View idm student gelöscht oder exmatrikuliert, wird die Matrikelnummer aus dem Attribut fauStudPK in das Attribut fauStudPKOld verschoben. Dieser Fall findet also z.B. Wiedereinschreiber.
Das zweite Matching versucht den neuen Studierendeneintrag anhand der Attribute Vorname, Nachname, Geburtsdatum und Geburtsort beliebigen Personeneinträgen im MD (normalerweise aus anderen Quellsystemen) zuzuordnen. Hierbei kommt das eigens erstellte Framework Data Linkage (DaLi) zum Einsatz. Eine komplette Beschreibung von DaLi würde den Rahmen dieses Artikels sprengen, weshalb hier nur die für die Einbettung in die Treiber-Logik notwendigen Teile erlaütert werden. Die grundlegende Funktionsweise einer frühen Version des Frameworks können den Folien des Vortrags von Krasimir Zhelev beim ZKI-Arbeitskreis für Verzeichnisdienste vom 06.Oktober 2009 3 entnommen werden.
Zum Zeitpunkt der Anbindung sollte das Matching-Modul möglichst ohne Abhängigkeit zu einem externen Dienst in die Treiber-Landschaft von Novell eingebettet werden. Zu diesem Zweck wurde aus DaLi ein einfaches Jar-Archiv entwickelt, welches nach Eingabe einer Person und möglicher Matching-Kandidaten die besten Treffer mit den Wahrscheinlichkeitswerten ausgibt. Die Einbindung des sog. ”Matching Processor“ erfolgt über eine Namespace- Definition der Matching Policy. Wie in Abbildung 3.2 ersichltlich wird die Java-Klasse de.rrze.idmone.utils.matching.MatchingProcessor an den Namespace matchingProcessor gebunden.
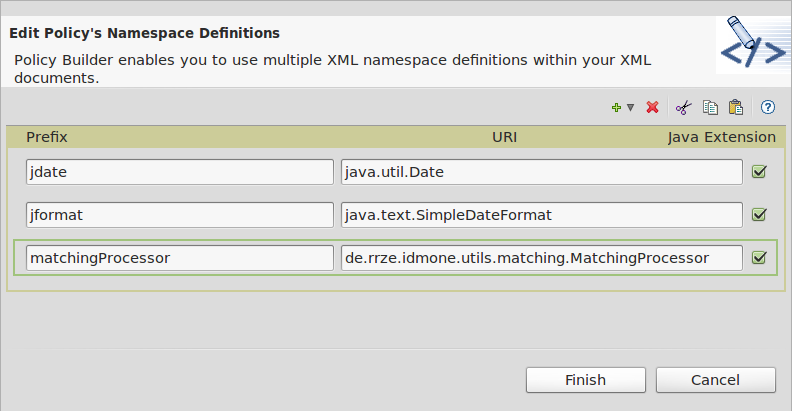
Abbildung 3.2: Matching Policy Namespace Definition
Die eigentliche Verwendung zeigt Abbildung 3.3. In der ersten Zeile wird der Matching Processor instanziert. Dabei werden die Attribute des neuen Personeneintrags übergeben. In der einfachen vereinfachten Version müssen alle möglichen Kandidaten im MD gesucht werden und mittels der Methode addNodeSet übergeben werden. Dabei kann die Methode mehrfach aufgerufen werden um weitere Suchergebnisse hinzuzufügen. Der Methodenaufruf nodeSetMatching startet die Auswertung. In der aktuellen Version vergleicht DaLi über 10000 Kandidaten innerhalb einer Zehntelsekunde. Die Beschränkung liegt hier eindeutig bei den LDAP-Suchen im MD. Nach der Auswertung können die Trefferwahrscheinlichkeiten abgefragt werden. Die Entscheidung ob der neue Eintrag mit einem existierenden Eintrag zusammengeführt wird bleibt so im Treiber bestehen.
Wird kein vorhandener Personeneintrag gematcht folgt die ”Creation Policy“. Hier findet die Überprüfung der zwingend erforderlichen Attribute statt. Fehlt eines dieser Attribute wird die Anlage verweigert. Sind alle erforderlichen Attribute vorhanden wird in der “Placement Policy” der DN des neuen Personeneintrags festgelegt. Dieser wird aus dem Personencontainer, einem eindeutigen Treiber-Prefix und der Matrikelnummer gebildet. Im Anschluss werden einige Attribute für einen neuen Personeneintrag gesetzt. Darunter fallen z.B. die initiale Gruppenmitgliedschaft und ein Anfangspasswort.
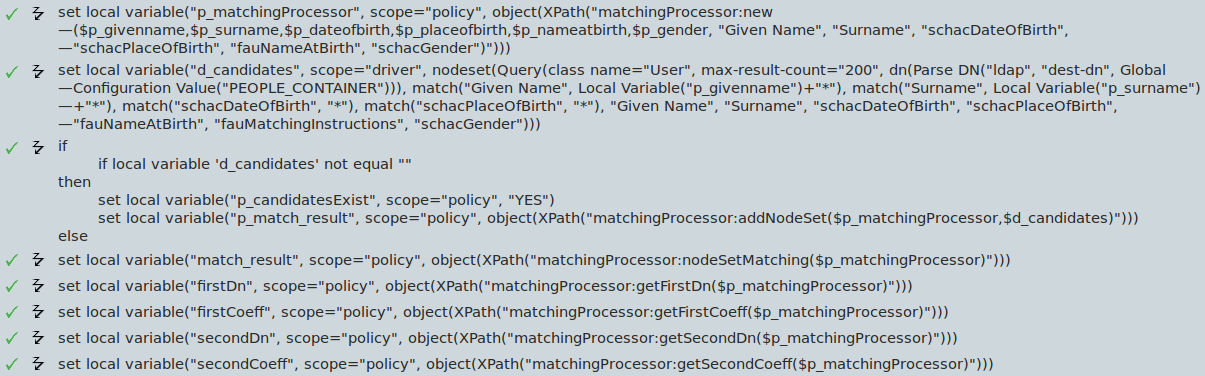
Abbildung 3.3: Verwendung des Matching Processor
In der ”Command Policy“ werden weitere Aktionen sowohl bei der Neuanlage als auch bei Aktualisierungen durchgeführt. So werden z.B. Löschungen in SOS in die bereits erwähnte Verschiebung der Matrikelnummer in das Attribut fauStudPKOld umgewandelt. Weiterhin findet eine Verlinkung mit dem evtl. bereits synchronisierten Informationen zum Studium statt, oder die Entscheidung ob eine vorhandene Kontaktadresse überschrieben werden soll.

Identity Management at the FAU – Student Management (Part 2)
Source Systems
If within the Identity Management (IdM) area the topic source system appears you might immediately think about personnel management. The provision of information about persons is surely the most important variety and most affective to the outside. Source systems however can be of very different kind. Among others the delivery of data for the organizational structure, mail addresses or functions belong to the category source systems. They all have in common that they provide information which is usually used of several systems.
HIS SOS
One of the first connected systems of the IdMS at the FAU was the student management, represented by HIS SOS. The provision of data basically consists of two database views:
• idm student • idm stg
idm student consists every needed information about the person of the student. Analogously idm stg contains every needed information about the studies. Both views are connected with the matriculation number which is at the same point the primary key for the IdM connection.
To readout both of the views Novells Identity Manager is used. To keep the effort for the user of the student management at a minimum, no trigger tables are used. The benefit of a trigger table would be the direct provision of all the changes. The driver can only notice changes through reading this table. If yes, it can, depending on the kind of trigger table, directly readout all the information about the existing changes, or can only get the affected data sets of the views. Without trigger tables the driver has to find the changes by itself via a comparison with its intern data copy. If there are no changes there would be no entry in the trigger table and the work of the driver would be done; without trigger tables all the entries have to be proven every time. At the moment the driver needs not more than 5 minutes (incl. SELECT) for both views with 60000 entries each. With a Polling Interval of currently 5 minutes the driver is at its limit with the current configurations.
The synchronization of both views in direction IdMS will be discussed in details in the following chapters. Therefore basic knowledge of the driver concept of Novell’s Identity Management is required. Illustration 3.1. gives a schematic overview.
Illlustration 3.1: Driver Sos
View idm student
Table 3.3 shows the schema mapping and filter adjustments between the view idm student and the object class user (aka inetOrg Person) in the Meta-Directory (MD). In the ”Input Transformation Policy“ the attribute gender (geschl) is implemented according to the in table 3.1. shown illustration. As in table 3.3 shown the attribute schacGender of the SCHema for ACademia 2 (SCHAC) is used which inserts the ISO 5218 standard. Therefore the data are interpreted as shown in table 3.2.
The ”Matching Policy“ basically consists of two parts. Generally it is tried to find an already existing person entry in the MD and to connect it with the new SOS entry. If the matching is successfully, the following tries are omitted; so the order is important.
The first try could be called “Standard-Matching”. An already from SOS synchronized entry should be recovered with it. If the entry has been deleted in SOS and was again created with the same matriculation number or the driver lost its associations because of other reasons (DirXML-Association), it should be recovered. To guarantee this a matching base on the primary key of the connection, in this case the matriculation number, is made. Here it is searched for the matriculation number in the following attributes:
1. Attribut fauStudPK
2. Attribut fauStudPKOld
HIS SOS
The search in the attribute fauStudPK makes sure that there aren’t two entries with the same matriculation number existing or created in the MD. The search in the attribute fauStudPKOld is supposed to find already ex-matriculated student entries. If entries in the View idm student are deleted or ex-matriculated, the matriculation number is moved from the attribute fauStudPK to the attribute fauStudPKOld. So this case finds e.g. again matriculated students.
The second matching tries to assign the new student entry according to the attribute given name, last name, date of birth and place of birth, to any personal entry in the MD (usually from different source systems). Therefore the self created Framework Data Linkage (DaLi) is used. A complete description of DaLi would go beyond the scope of this article and that is the reason why only the embedding of the driver logic are explained. The fundamental operation mode of an earlier version of the framework can be found in the slides of a presentation by Krasimir Zhelev of the ZKI-Workinggroup for account services on 6th October 2009 3.
At the moment of the connection, the matching module should be embedded into the driver-landscape of Novell preferably without any dependency to an external service. For this reason DaLi was developed from a simple Jar-Archive which displays the best matches with the highest rates on possibility after the insertion of a person and possible matching candidates. The embedding of so called “Matching Processor” results from a namespace definition of the matching policy. As shown in illustration 3.2 the Java-class de.rrze.idmone.utils.matching. MatchingProcessor is bound to the namespace matchingProcessor.
Illustration 3.2: Matching Policy Namespace Definition
The actual use is shown in illustration 3.3. In the first line the matching processor is instanced. Therefore the attributes of the new personal entry are committed. In the easiest simplified version ever candidate has to be find in the MD and be delivered with the addNodeSet method. Therefore the method can be multiply selected to add further search results. The method request nodeSetMatching starts the analysis. In the current version DaLi compares over 10000 candidates within the tenth of a second. The limitation here lies definitely in the LDAP-search in the MD. After the analysis the possibility of a hit can be requested. The decision if a new entry should be combined with an already existing entry will stay within the driver.
If there is no existing personal entry matched, the “Creation Policy” follows. Here the testing of the obligatory attributes happen. If one of the attributes is missing the construction is denied. If every necessary attribute is available, a new person entry is defined in the “Placement Policy” of the DN in the new person entry. This is build from the person container, a definite driver prefix and the matriculation number. Subsequently some attributes are set for a new person entry. Within these are e.g. the initial group membership and an initial password.
Illustration 3.3: Use of the Matching Processor
In the ”Command Policy“ further actions are performed as well with a new entry as with updates. So e.g. deletion in SOS are converted in the already mentioned movement of the matriculation number into the fauStudPKOld attribute. Furthermore a linkage between the possibly already synchronized information according to the studies takes place, or the decision if an already existing contact address should be overwritten.