Recently, in the HPC services office…
(… phone rings …)
“Computing Center, HPC services. How can I help you?”
“Yes, High Performance Computing.”
“You want to use our GPGPU cluster? Great! The load on this baby could be higher anyway. It’s hard to believe, but people seem to avoid it like the plague (jovial laughter). Do you have a code that runs on GPUs already?”
“I see, the compiler should be able to handle this. But the code is SIMD vectorized for standard processors, right?”
“No, this has nothing to do with cell phones. SIMD means ‘Single Instruction Multiple Data,’ i.e., several operations can be performed on different operands with a single machine instruction. If that works, chances are that the program can be run efficiently on a GPU as well. After all, GPUs implement the SIMD principle quite extensively.”
“Hm? I think I don’t understand…”
“Ah, ok. No, you don’t have to learn assembly programming to do this. But you may have to think a little more about how the compiler looks at your code. Often you can help it by supplying additional information, like source directives. And of course you need to use a compiler that understands what SIMD is. Alas, the GNU compilers don’t have a clue about it, mostly. By the way, how have you parallelized the code?”
“Um, no. Compilers can’t help you much here, except for very simple cases where a 10-year-old can do it just as well. But you do have to parallelize. How do you want to draw a meaningful comparison to the GPU version?”
“What do you mean, you don’t need to do this?”
“Um, yes, I think I’ve seen this paper recently. It should be on my desk somewhere… (paper rustling) And what exactly are you referring to?”
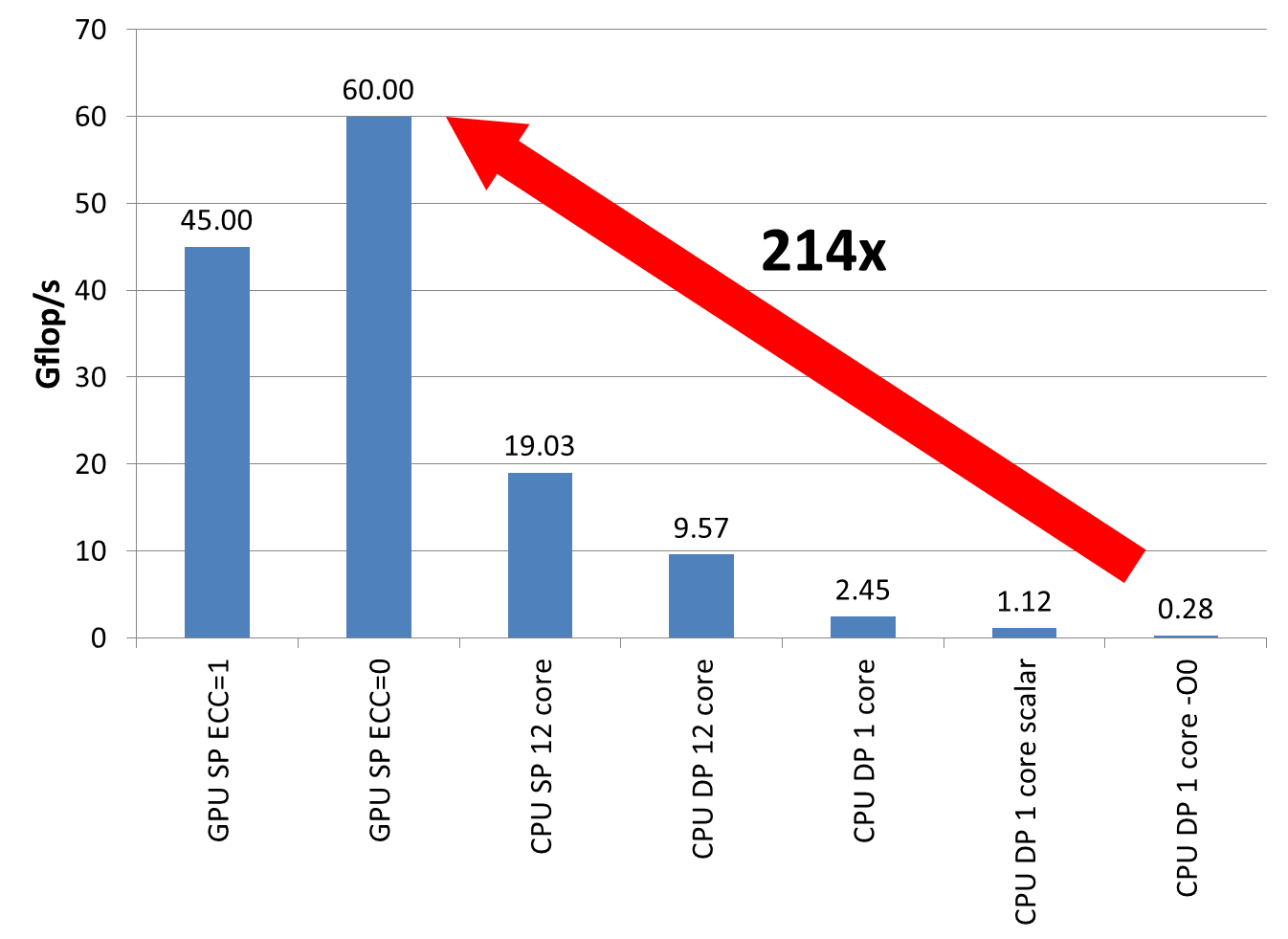
“Section 4.3, just a sec… here we are: ‘As shown in Fig. whatever, we have achieved a 400x speedup on an NVIDIA Tesla GPU as compared with our CPU implementation.’ (long pause)”
“Sorry, no, I’m still here. I’ve just been looking for the details of the CPU implementation. One moment… (longer pause) Ok, here’s something in the caption of the pretty CFD visualization: ‘In order to avoid issues with OpenMP parallelization we have run the CPU version on a single core.’ Wow. This has to sink in. And if I’m not mistaken, they compare a single-precision GPU code with a double precision version on the CPU. Truly hilarious.”
“No, I’m not making fun of those scientists. But ‘scientists’ is not the word I would use. They obviously think that everyone else is stupid.”
“Why? Because a factor of 400 is impossible. Neither the floating-point peak performance nor the memory bandwidth of the GPU is 400 times larger than that of a current standard compute node, or a chip, or even a single core. So they must have fabricated a slow CPU code on purpose. Realistically one may expect a factor of 2-4 if you compare a reasonably optimized CPU code on a single node with a single GPU, and use the same precision on both.”
“Yes, I agree. 2-4 isn’t bad at all. But that’s just counting the raw GPU. How would the data transfer affect the performance of you code? Can you estimate this?”
“Well, somehow the data must be brought into the GPU and the results must be copied back so that they don’t start rotting over there…”
“Yes (sighing with resignation). Compilers are smart. But there are limits. If you copy the whole problem through the PCI bus after every step, the only way to exploit the performance advantage of the GPU is to perform ridiculously many flops. It’s all a matter of code balance.”
“Code balance tells you how much data transfer your code needs per executed floating-point operation – and you have to count everything, including communication via buses, the network, the memory interface, etc. This can add up to quite some data volume. And then you compare with the amount of data the hardware can transfer per peak flop executed, which gives you an estimate for the performance.”
“You don’t know how many flops and how much data transfer your code needs? Can’t you just count that by looking at it? In most cases, compute time is spent in a very limited number of numerical kernel loops.”
“No, the compiler doesn’t count that for you (keeping composure with obvious effort). It’s also a matter of optimization; perhaps one can reduce the data transfers a bit. One would have to take a look at the code.”
“The compiler? (devastated) Yes, you should try that. Definitely… No listen, people are much too enthusiastic about the compiler’s abilities. Compilers can not read your mind, they can’t even look through the standard C++ template tricks that programmers are so fond of. Let alone generate optimal code for GPUs.”
“Ok, err, sorry, are you crying? (nonplussed) Please don’t. May I suggest that we sit together over a cup of coffee and I give you a crash course in basic performance modeling? Don’t worry, everything’s going to be alright. There, there…”