(See the prelude for some general information on what this is all about)
There is actually a very clear definition of the term “performance” in HPC: “performance” is “work” divided by “time.” You may think about “work” as “the problem”; occasionally, Flops is a possible (but easily manipulable) measure. “Time” is the overall wall-clock time to do the work, including everything that needs to be done but counts as overhead, such as communication and synchronization. If you look at performance with respect to parallel resources, i.e., if you want to know how performance scales with the number of workers, the same formula applies – to strong and to weak scaling alike.
Now sometimes the performance results for your parallel program are … mediocre. There may be two reasons for this:
- Scalability is good but your single-core or single-node performance sucks. This is may be a consequence of your applying stunt 2, either by accident or on purpose. If you only show speedups (see stunt 1) you will be fine; however, sometimes it is not so easy to get away with this.
- Single-core and single-socket performance is good (i.e., you understand and hit the relevant bottleneck[s]), but scalability is bad. You know the culprits: load imbalance, insufficient parallel work, communication, synchronization.
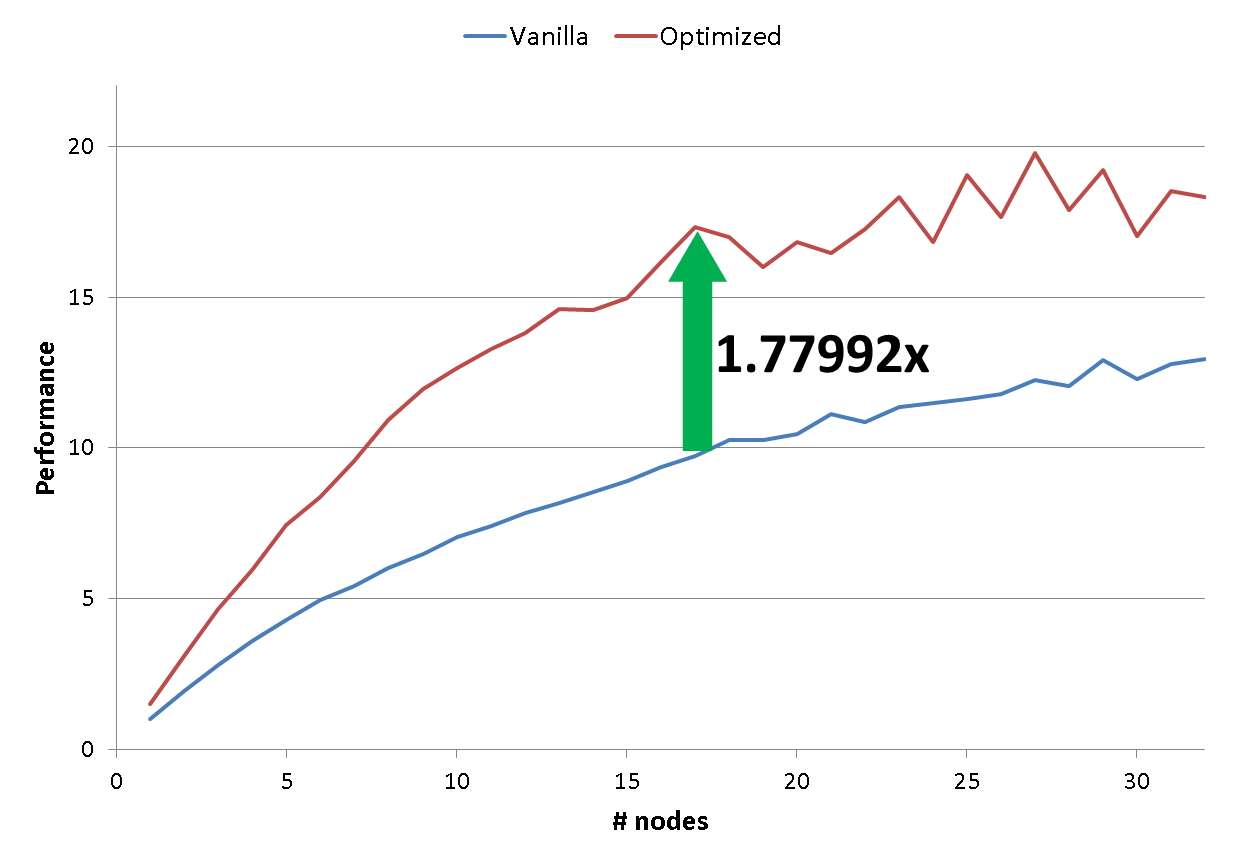
Either way, you probably don’t want to show actual performance numbers or data about time to solution. As it happens there is a host of options you can choose from. You can certainly play around with the “time” component in the performance calculation, as shown in stunt 5 and stunt 9, or quietly invoke weak scaling as shown in stunt 4. Here are some popular and more imaginative examples:
Employ “floptimization:” Throw in some extra Flops to make the CPU perform more “work” at hardly any extra cost; often there is at least some headroom in the floating-point pipelines when running real applications. Accumulating something in a register is a classic:
for(s=0.0, i=0; i<N; ++i) {
p[i] = f(q[i]); // actual work
s += p[i]; // floptimization
}
Even if the sum over all elements of p[] is not needed at all, it’s one more Flop per iteration, it boosts your flop rate, and it will usually not impact your time to solution! If you do it right, only the sky is the limit.
Use manpower metrics: Developing code is expensive, so you can take manpower into account. State that your superior hardware or software environment enabled you to get a working code in less than one week, which amounts to so and so many “man-hours per GFlop/s.” This can be extended to other popular software metrics.
Play the money card: “GFlop/s per Dollar” may also be useful, especially if you compare different systems such as your average off-the-shelf departmental cluster and the big DoE-paid iron.
Go green: Since everyone in HPC today is all mad about saving energy, use “Joules per Flop,” “GFlop/s per Watt,” “CO2 equivalents,” “Joule-seconds,” “Joule-seconds-squared,” or any other combination of metrics that shows the superiority of your approach in terms of “green” or “infrastructure-aware” computing. Moreover, energy to solution is almost proportional to runtime, so you can rename your paper on “Performance Optimization of a Kolonovski-Butterfield Solver” to “Energy Optimization of a Kolonovski-Butterfield Solver” and turn a boring case study into bleeding-edge research.
Blame the wimpy hardware: For multi- or many-core chips, per-core or per-thread metrics mask the inherent bottlenecks and are great for bashing your competitors. For instance, when comparing a multi-core CPU with a GPGPU you could declare that “the available bandwidth per thread is 122 times higher on the CPU than on the GPGPU.” Oh wait – make that 121.68 times.
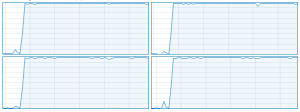
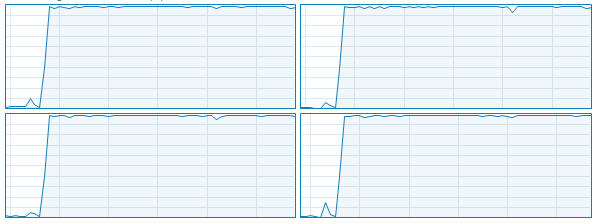
Figure 1: Windows task manager is your friend: Four cores, all of them 100% utilized – that’s performance!
Boast frantic activity: MIPS (millions of instructions per second) or, equivalently, IPC (instructions per cycle) are perfect higher-is-better metrics if true performance is low. IPC can be boosted on purpose by several means: You can use a highly abstracting language to make the compiler generate a vast amount of instructions for simple things like loading a value from memory, or disable SIMD so that more instructions are executed for the same amount of work. Waiting in OpenMP barriers or MPI functions is also good for a large IPC count, since it often involves spin-waiting loops. You can use special options to disable compiler optimizations which have the potential to change numerical results (such as common subexpression elimination). But take care: If that means moving slow operations like floating-point divides into an inner loop, the IPC value will go down dramatically.
Fight the evil: State that your new code or new algorithm shows a factor of X fewer cache misses compared to the baseline. Cache misses are the black plague of HPC, so nobody will doubt your success. And they are just as easy to manipulate as Flops. Combining with the “go green” strategy is straightforward: Cache misses cost vast amounts of energy (they say), so you can be green and good at the same time!
Wow the management: State that “all processors are 100% utilized, so the code makes perfect use of the available resources.” Windows task manager is the perfect tool to show off with a stunt like this (see Fig. 1), but “top” under Linux works fine, too:
PID VIRT RES SHR %CPU %MEM TIME+ P COMMAND
2318 492m 457m 596 98.6 22.9 0:35.52 2 a.out
2319 492m 457m 596 98.6 22.9 0:35.53 0 a.out
2321 492m 457m 596 98.6 22.9 0:35.50 1 a.out
2320 492m 457m 596 97.6 22.9 0:35.44 3 a.out
In summary, metrics are your wishing well: Find the right metric and any code will look good.
This stunt is essentially #9 of Bailey’s original “Twelve ways to fool the masses.”