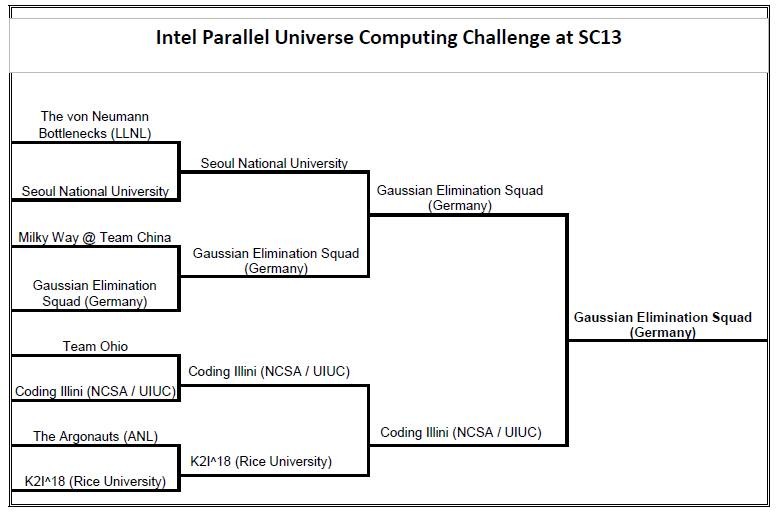
Final team bracket for the Intel Parallel Universe Computing Challenge
We’ve made it! The final round against the “Coding Illini” team, comprising members from the University of Illinois and the National Center for Supercomputing Applications (NCSA), took place on Thursday, November 21, at 2pm Mountain Time. We were almost 30% ahead of the other team after the trivia, and managed to extend that head start in the coding challenge, which required the parallelization of a histogram computation. This involved quite a lot of typing, since OpenMP does not allow private clauses and reductions for arrays in C++. My request for a standard-sized keyboard was denied so we had to cope with a compact one, which made fast typing a little hard. As you can see in the video, a large crowd had gathered around the Intel booth to cheer for their teams.
Remember, each match consisted of two parts: The first was a trivia challenge with 15 questions about computing, computer history, programming languages, and the SC conference series. We were given 30 seconds per question, and the faster we logged in the correct answer (out of four), the more points we got. The second part was a coding challenge, which gave each team ten minutes to speed up a piece of code they had never seen before as much as possible. On top of it all, the audience could watch what we were doing on two giant screens.

The Gaussian Elimination Squad: (left to right) Michael Kluge, Michael Ott, Joachim Protze, Christian Iwainsky, Christian Terboven, Guido Juckeland, Damian Alvarez, Gerhard Wellein, and Georg Hager (Image: S. Wienke, RWTH Aachen)
In the first match against the Chinese “Milky Way” team, the code was a 2D nine-point Jacobi solver; an easy task by all means. We did well on that, with the exception that we didn’t think of using non-temporal stores for the target array, something that Gerhard and I had described in detail the day before in our tutorial! Fortunately, the Chinese had the same problem and we came out first. In the semi-final against Korea, the code was a multi-phase lattice-Boltzmann solver written in Fortran 90. After a first surge of optimism (after all, LBM has been a research topic in Erlangen for more than a decade) we saw that the code was quite complex. We won, but we’re still not quite sure whether it was sheer luck (and the Korean team not knowing Fortran). Compared to that, the histogram code in the final match was almost trivial apart from the typing problem.

According to an enthusiastic spectator we had “the nerdiest team name ever!”
After winning the challenge, the “Gaussian Elimination Squad” proudly presented a check for a $25,000 donation to the benefit of the Philippines Red Cross.
I think that all teams did a great job, especially when taking into account the extreme stress levels caused by the insane time limit, and everyone watching the (sometimes not-so-brilliant) code that we wrote! It’s striking that none of the US HPC leadership facilities made it to the final match – they all dropped out in the first round (see the team bracket above).
The Gaussian Elimination Squad represented the German HPC community, with members from RWTH Aachen (Christian Terboven and Joachim Protze), Jülich Supercomputing Center (Damian Alvarez), ZIH Dresden (Michael Kluge and Guido Juckeland), TU Darmstadt (Christian Iwainsky), Leibniz Supercomputing Center (Michael Ott), and Erlangen Regional Computing Center (Gerhard Wellein and Georg Hager). Only four team members were allowed per match, but the others could help by shouting advice and answers they thought were correct.