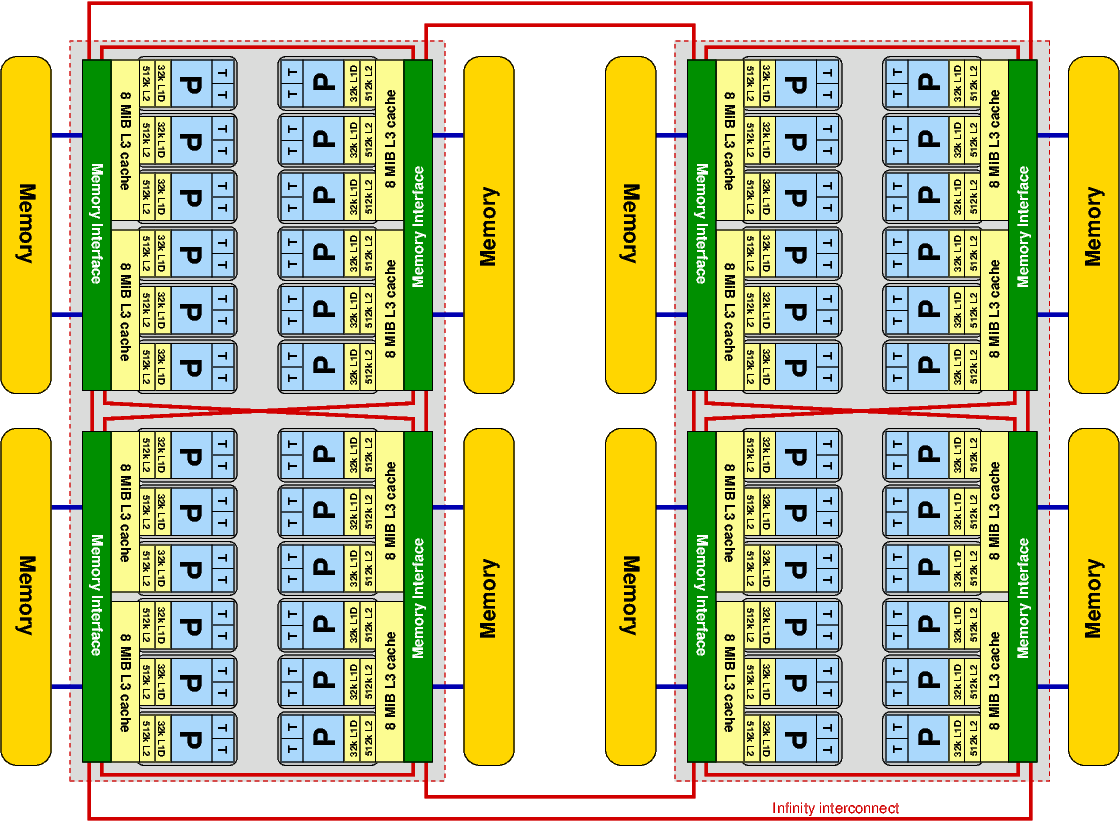
Fig. 1: A dual-socket AMD Epyc 7451 node with four “Zeppelin” dies per socket (eight ccNUMA domains per node). Each 8 MiB L3 cache is shared by three cores, i.e., half the die.
(See the prelude for some general information on what this is all about)
Real scientists are not bothered by details such as multicore, cache groups, ccNUMA, SMT, or network hierarchies. Those are just parts of a vicious plot to take the fun out of computing. Ignoring the associated issues like bandwidth bottlenecks, NUMA locality and contention penalties, file system buffer cache, synchronization overheads, etc., will make them go away.
If you present performance data and people ask specific questions about affinity and topology awareness, answer that it’s the OS’s or the compiler’s job, or the job of some auto-tuning framework, to care about those technicalities. Probably you can show off by proving that your code scales even though you run it without topology awareness; this can be easily achieved by applying Stunt 2 – just slow down code execution enough to make all overheads vanish.
If you run into problems like mysterious performance fluctuations, or performance being too low altogether (a direct but often ignored consequence of applying Stunt 2), blame the system administrators. Being lowly minions of top-achieving scientists like you, they will have the time to figure out what’s wrong with their hardware. If they tell you it’s all your fault, send a scathing e-mail to their boss and cc: your university president or company CTO, just for good measure. Finally, if all else fails, publish a paper at a high-profile conference stating that the hardware of manufacturer X shows horrible performance, especially together with compiler Y and library Z, and that the cluster you had access to was too small to get the results that you wanted in time. That’s why you are about to write a generous research proposal for a federal supercomputing facility. Anything less just won’t cut the mustard!