IMB multi-mode Ping-Pong demystified?
Everybody knows the ubiquitous PingPong benchmark, first published in the Pallas MPI benchmarks and today contained in Intels IMB suite. Using one process on each node and plotting bandwidth versus message size, you see the well-known behaviour – saturating bandwidth for large messages and latency domination for small ones (blue curve – measurements were done on our Woody cluster between nodes that are connected to a common IB switch nodeboard, i.e. with DDR speed):
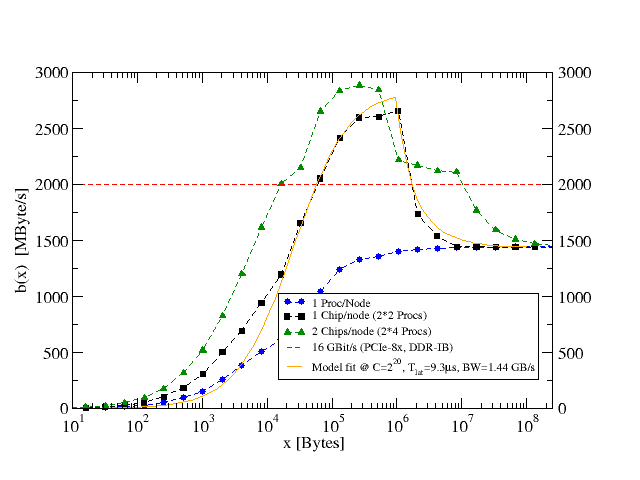
If you run this code in multi-mode, i.e. two or more processes on one node sending and two or more on the other node receiving, the bandwidth pattern changes considerably (black squares). There is a significant “overshoot” for medium-sized messages and a sudden drop at about 1 MByte. Eventually the saturation bandwidth is the same as in the simple case.
It turns out that one can explain this, at least for the 2-2 case, by assuming that MPI (or the IB driver or whoever) splits messages that are larger that a certain limit (e.g., 1 MByte) into chunks and transmits/receives those chunks alternating between the two connections. Using this model and fitting the parameters we can predict the multi-mode Ping-Pong bandwidth quite well (orange curve). In the 3-3 case, however, things get more complicated (green curve) and there is an additional plateau. I’m not sure whether one can really extend the model to encompass this effect as well.
If you are interested, the gory details have been written up: mm-pingpong.pdf