(See the prelude for some general information about what this is all about.)
Have you ever been stuck with a slow machine, but needed to compare it with something else (much faster) you didn’t have the wits or guts to use? Or even worse, you want to sell one of those slow machines and no matter what you do, you just can’t get your codes run faster than your competition? This stunt may be for you. On a very simple level, if we define “speedup” as
\large S(N)=\frac{\text{work/time with \textit{N} workers}}{\text{work/time with 1 worker}}it is clear that it is a gift from heaven: If S\approx N we speak of “good scalability”, but there is no indication of how fast a certain problem can be solved, or even how many “operations” per time unit are performed. Note that the speedup definition above works for strong and weak scaling scenarios alike.
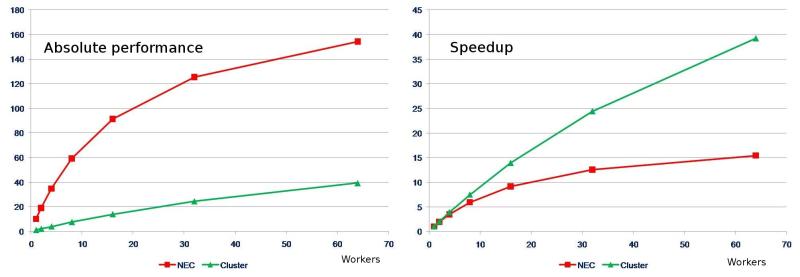
In this example we see a comparison between some “big iron” machine, let’s call it “NEC”, and a standard cluster, which you would like to show off in your presentation. As you can see on the left, the big machine outperforms the cluster by far on a worker-by-worker basis; however, if the one-worker performance is normalized to one we see that the cluster “scales better”. Whatever the particular reasons for this may be, presenting scalability (or speedup) instead of absolute performance is key.
Certainly, not all audiences are so easily deceived, but labeling your talk with the word “executive” somewhere in the title will fend off the geeks and leave you with a convenient flock of suits who will eat what you give them.
Interesting and funny posts 🙂 Certainly recognizable 😉
I’m hesitant to agree on this point however.
We often compare different toolsets on the same architecture. Because our own toolset generalizes some things it introduces some overhead, therefore we often present absolute scalability figures. This makes sense to me, we want to compare multi-core runtimes and are not interested in optimizing the sequential case (it is even slowed down do to the overhead).
Also I know that presenting the relative scalability will even make our toolset look better, but this does not seem fair.
I guess what I am trying to say is that having abolute scalability figures eliminates your point 2 (intentionally slowing down the base case).
“… we want to compare multi-core runtimes and are not interested in optimizing the sequential case”
This is exactly what I object to. A scientist wants to solve a problem, usually in the least possible amount of time. Hence, scalability is not important but time to solution is. Why spend more resources (cores, power) when you can reach the same goal by optimizing the code so that it runs just as fast on fewer cores? Moore’s Law is not there to compensate for lousy (slow) code. What I want to have is code that utilizes the hardware to its theoretical limit, i.e., that exhausts the relevant bottleneck. And finally, sequential instructions are executed on the individual cores, so sequential performance is the first thing to look at.
As to your second comment, you have a point – Stunt 1 and 2 are related. I see Stunt 1 as a way to hide bad code performance or present it in a better light, while Stunt 2 describes ways to get there (i.e., boost scalability by slow code intentionally).
Interesting to see your point of view. I get it, instead of parallelizing for example an O(n^3) algorithm it is more effective to employ a O(n^2) algorithm. Or instead of parallelizing an sandboxed or scripted implementation, it would be better to take the time to implement it in C with some good data structures.
However, the only way to speedup our sequential problem, is by employing “assembly code and other low-level language constructs” (stunt 3). It is namely a rather trivial implementation of semantics for which we already generate efficient C code. And we are not interested in wasting our scientific resources in redoing this in a limited (non-portable and non-maintainable) but optimized way. This changes the game a little.
So we connect in a generic way to existing code, adding about 30-50% overhead and then parallelize it. Now with two cores we beat the other optimized tools (also with two cores!) already. Once you demonstrate this and better scalability, you could argue that the original tools can also employ your design. This would probably yield almost the same scalability, but with the optimal sequential base case.
Your point remains valid: it is harder to compare scalability when you show the absolute speedups. I would be glad to do that the next time, like I said, this would make our tool even look better. But the reason I bring this up, is to show that not all scientists, who show absolute speedups, are trying to cook their papers.
In general, I experience that there are many factors to take into account when you try to make an honest experimental comparison between parallel implementations. And often there is really to few emphasis on this. So I was happy reading your blogpost.