A question came up on the OpenMP mailing list today concerning scalability of simple array summation on an Opteron processor. I have done some tests with the following code, using the Intel C++ compiler version 9.1:
#pragma omp parallel for private(j) reduction(+: sum)
#pragma vector always
for (j = 0; j < N; j++){
sum += array2[j];
}
There is a loop around that to ensure that for small sizes we actually see the cache effect. Here is the result:
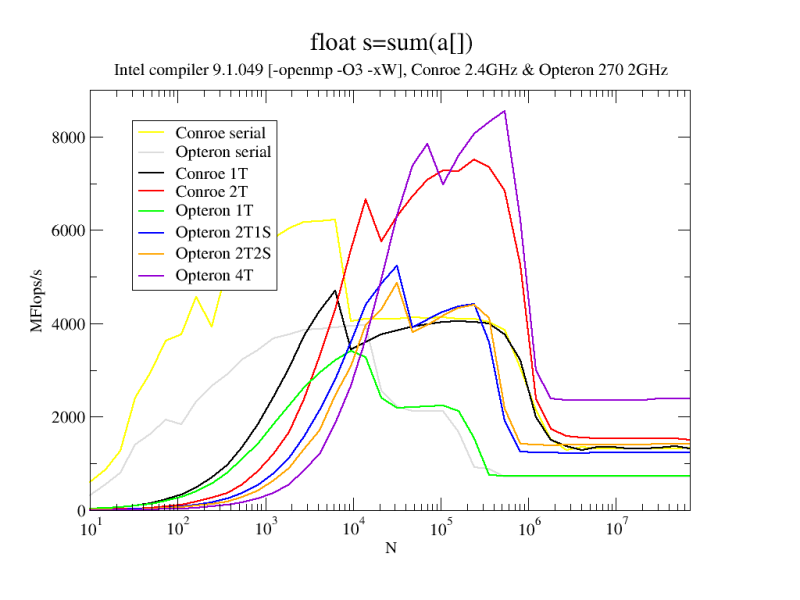
The number of threads (1T, 2T,…) is indicated. In case of the Opteron system, this was a 2-socket dual-core 2GHz box and the 2-thread data was correspondingly measured on one (1S) or two (2S) sockets, respectively. Proper NUMA placement was implemented. The “Conroe” system is my standard Core2 workstation.
Data on purely serial runs (no -openmp) is shown for reference. In contrast to low-level benchmarks like the stream or vector triads which have more read streams and at least one write stream, there seems to be a lot of “headroom” for the second thread even for large N on an Opteron socket.